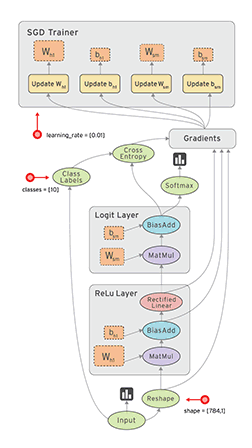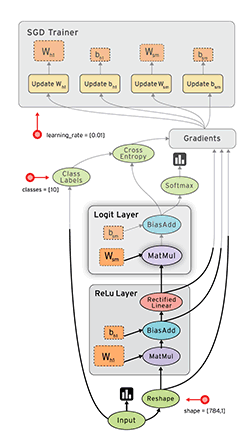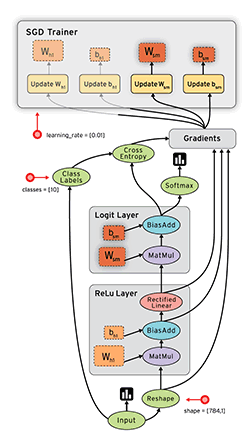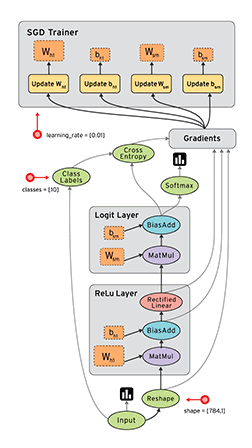
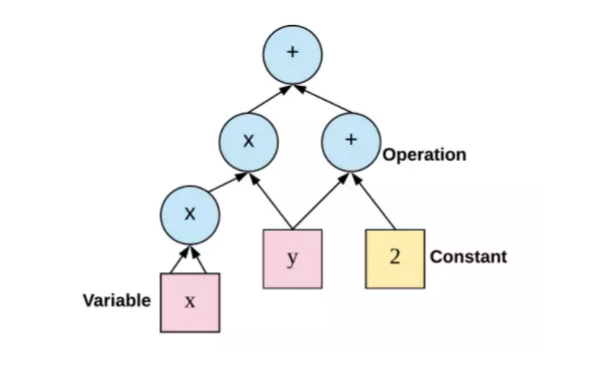
# linear_model: y = W*x + b W = tf.Variable([.1], dtype=tf.float32) b = tf.Variable([-.1], dtype=tf.float32)
x = tf.placeholder(tf.float32, name='x') y = tf.placeholder(tf.float32, name='y')
# create linear model linear_model = W * x + b
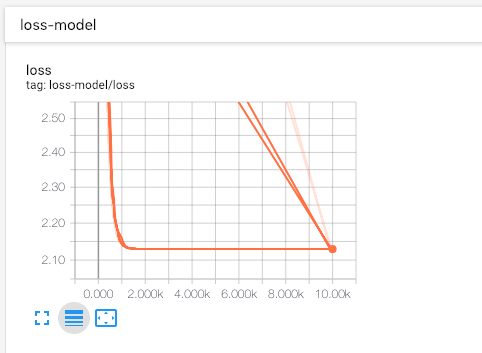
# create loss model with tf.name_scope("loss-model"): loss = tf.reduce_sum(tf.square(linear_model -y)) #Add scalar to the output of the loss model to observe the convergence curve of loss tf.summary.scalar("loss", loss)
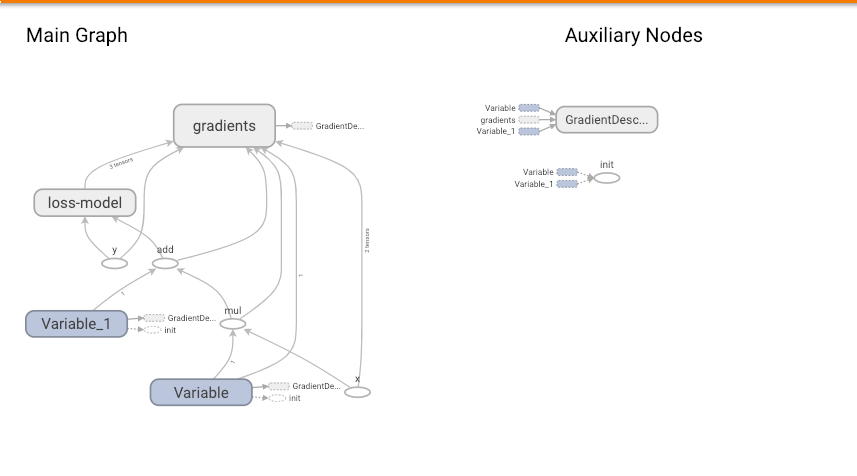
# create a optimizer use Gradient Descent algorithm. optimizer = tf.train.GradientDescentOptimizer(0.001) train = optimizer.minimize(loss)
# merges all sunmaries collected in the default graph merged = tf.summary.merge_all()
#All data generated by the model run is saved to the /tmp/tensorflow folder for use by TensorBoard writer = tf.summary.FileWriter('/tmp/tensorflow', sess.graph)
# Training 10,000 times for i in range(10000): # Pass in merge during training summary, _ = sess.run([merged, train], {x: x_train, y: y_train}) # collected output train data writer.add_summary(summary, i)
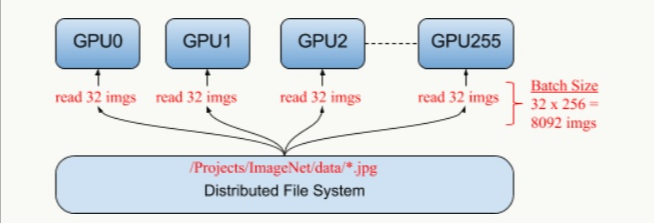
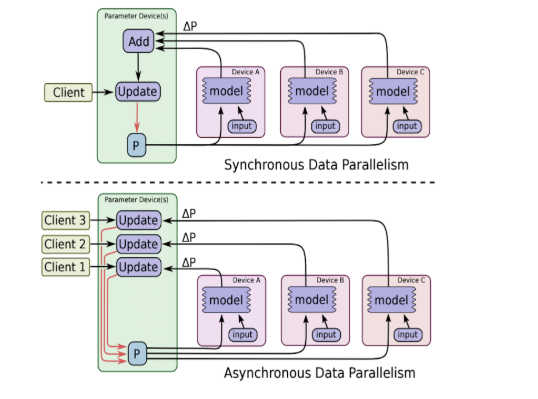
数据并行可以是同步(synchronous),也可以是异步(asynchronous)。所谓同步指的是所有的设备都是采用相同的模型参数来训练,等待所有设备的batch训练完成后,收集它们的梯度然后取均值,然后执行模型的一次参数更新。这相当于通过聚合很多设备上的batch形成一个很大的batch来训练模型,通过这种方式能使学习速率得到不错的效果。同步训练看起来不错,但是实现需要各个设备的计算能力均衡,而且要求集群的通信也要均衡,类似木桶效应,一个拖油瓶会严重拖慢训练进度,所以同步训练方式相对来说训练速度会慢一些。异步训练中,各个设备完成一个mini-batch训练之后,不需要等待其它节点,直接去更新模型的参数,这样总体会训练速度会快很多。但是异步训练的一个很严重的问题是梯度失效问题(stale gradients),刚开始所有设备采用相同的参数来训练,但是异步情况下,某个设备完成一步训练后,可能发现模型参数其实已经被其它设备更新过了,此时这个梯度就过期了,因为现在的模型参数和训练前采用的参数是不一样的。由于梯度失效问题,异步训练虽然速度快,但是可能陷入次优解(sub-optimal training performance)。异步训练和同步训练在TensorFlow中不同点如下图所示:
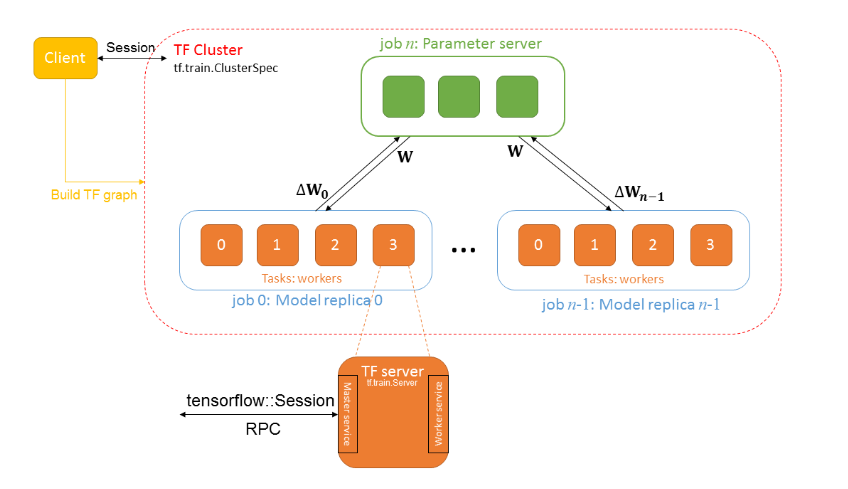
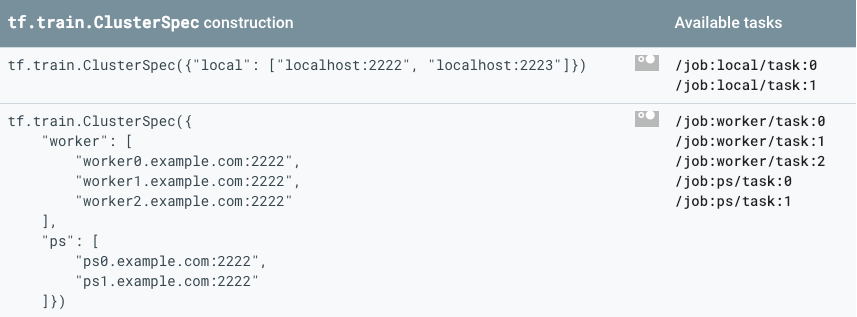
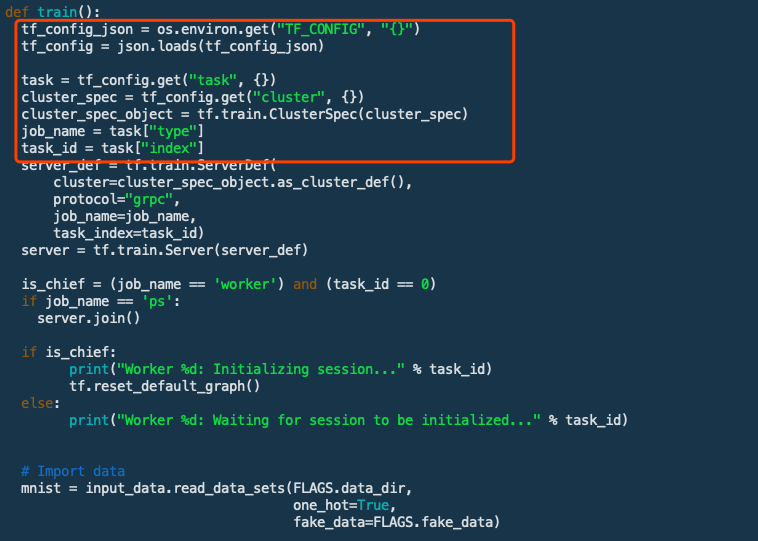
# Create a cluster from the parameter server and worker hosts. cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# Create and start a server for the local task. server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
if FLAGS.job_name == "ps": server.join() elif FLAGS.job_name == "worker":
# Assigns ops to the local worker by default. with tf.device(tf.train.replica_device_setter( worker_device="/job:worker/task:%d" % FLAGS.task_index, cluster=cluster)):
# Build model... loss = ... global_step = tf.contrib.framework.get_or_create_global_step()
# The StopAtStepHook handles stopping after running given steps. hooks=[tf.train.StopAtStepHook(last_step=1000000)]
# The MonitoredTrainingSession takes care of session initialization, # restoring from a checkpoint, saving to a checkpoint, and closing when done # or an error occurs. with tf.train.MonitoredTrainingSession(master=server.target, is_chief=(FLAGS.task_index == 0), checkpoint_dir="/tmp/train_logs", hooks=hooks) as mon_sess: whilenot mon_sess.should_stop(): # Run a training step asynchronously. # See <a href="./../api_docs/python/tf/train/SyncReplicasOptimizer"><code>tf.train.SyncReplicasOptimizer</code></a> for additional details on how to # perform *synchronous* training. # mon_sess.run handles AbortedError in case of preempted PS. mon_sess.run(train_op)
if __name__ == "__main__": parser = argparse.ArgumentParser() parser.register("type", "bool", lambda v: v.lower() == "true") # Flags for defining the tf.train.ClusterSpec parser.add_argument( "--ps_hosts", type=str, default="", help="Comma-separated list of hostname:port pairs" ) parser.add_argument( "--worker_hosts", type=str, default="", help="Comma-separated list of hostname:port pairs" ) parser.add_argument( "--job_name", type=str, default="", help="One of 'ps', 'worker'" ) # Flags for defining the tf.train.Server parser.add_argument( "--task_index", type=int, default=0, help="Index of task within the job" ) FLAGS, unparsed = parser.parse_known_args() tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
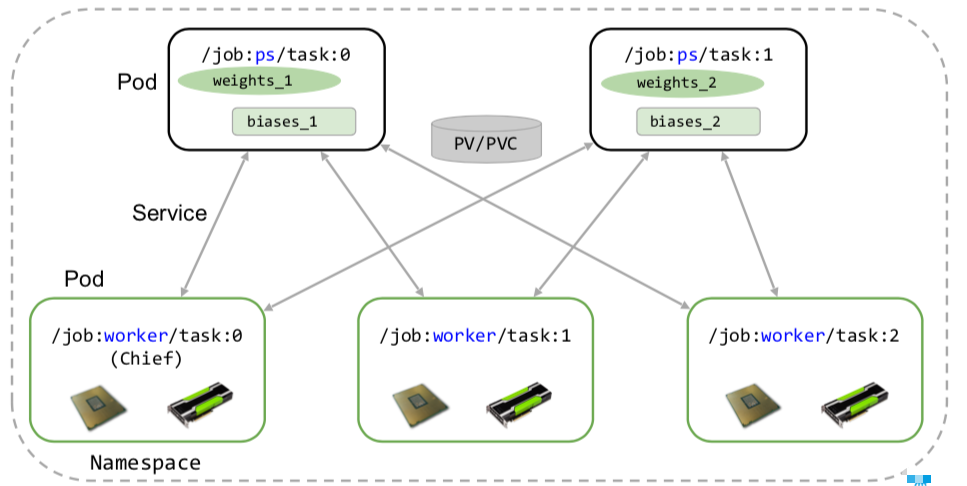
# kubectl create -f mnist_multi_gpu.yaml tfjob.kubeflow.org/dist-mnist-for-e2e-test created
查看tfjobs任务是否创建成功,并且状态是否处于ready状态:
1 2 3
# kubectl get tfjobs NAME AGE dist-mnist-for-e2e-test 47s
1 2 3 4 5
# kubectl get pods NAME READY STATUS RESTARTS AGE dist-mnist-for-e2e-test-ps-01/1 Running 053s dist-mnist-for-e2e-test-worker-01/1 Running 053s dist-mnist-for-e2e-test-worker-11/1 Running 053s
# docker logs -f 265d4ae426d6 /usr/local/lib/python2.7/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`. from ._conv import register_converters as _register_converters 2019-01-3007:37:21.960547: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA 2019-01-3007:37:22.285116: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1105] Found device 0 with properties: name: Tesla K80 major: 3minor: 7 memoryClockRate(GHz): 0.8235 pciBusID: 0000:05:00.0 totalMemory: 11.92GiB freeMemory: 11.68GiB 2019-01-3007:37:22.285154: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1195] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Tesla K80, pci bus id: 0000:05:00.0, compute capability: 3.7) 2019-01-3007:37:27.471978: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> dist-mnist-for-e2e-test-ps-0:2222} 2019-01-3007:37:27.472009: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> localhost:2222, 1 -> dist-mnist-for-e2e-test-worker-1:2222} 2019-01-3007:37:27.474101: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://localhost:2222 WARNING:tensorflow:From /app/main.py:202: __init__ (from tensorflow.python.training.supervisor) is deprecated and will be removed in a future version. Instructions for updating: Please switch to tf.train.MonitoredTrainingSession 2019-01-3007:37:28.924878: I tensorflow/core/distributed_runtime/master_session.cc:1017] Start master session 23fe02df8676c506 with config: Worker 0: Initializing session... Extracting /train/tensorflow/input_data/train-images-idx3-ubyte.gz Extracting /train/tensorflow/input_data/train-labels-idx1-ubyte.gz Extracting /train/tensorflow/input_data/t10k-images-idx3-ubyte.gz Extracting /train/tensorflow/input_data/t10k-labels-idx1-ubyte.gz Accuracy atstep0: 0.1445 Accuracy atstep10: 0.7489 Accuracy atstep20: 0.8691 Accuracy atstep30: 0.8885 Accuracy atstep40: 0.895 Accuracy atstep50: 0.8975 Accuracy atstep60: 0.9098 Accuracy atstep70: 0.9185 Accuracy atstep80: 0.9229 Accuracy atstep90: 0.9283 Adding run metadata for99