适合AI场景的调度器 - Gang-Schedule
使用kubeflow结合kubernetes进行大规模分布式训练时,由于AI场景下对任务的调度需要: all or nothing, multi-tenant task queue, task priority, preemption,gpu affinity等条件,但是kubernetes默认的调度器对这些条件还没有完全的支持,幸运的是kubernetes社区孵化了一个适合训练的调度器kube-batch。
AI 场景下的调度有何不同?
- gang-schedule(all or nothing)
- multi-tenant task queue
- task priority
- preemption
- gpu affinity
第一点比较重要的就是gang-schedule。gang-schedule是什么概念? 用用户提交一个 batch job, 这个batch job 包含100个任务,要不这100个任务全部调度成功,要么一个都调度不成功。这种all or nothing调度场景,就被称作:gang-schedule,通常用于集群资源不足的场景,比如 AI 场景下调用GPU资源。
第二点就是AI场景需要提供多住户的任务队列。因为GPU资源是非常宝贵的,经常会出现集群资源不可用的情况。当不可用时,需要有租户或者任务的优先级,并且每个租户需要有对应的优先级队列,队列里面又有任务优先级,设计不同的优先级住户之间的资源抢占,或者同一个租户不同优先级任务的资源抢占。另外GPU Affinity的调度能力,可以提高模型的训练性能,也是scheduler需要考虑的事情。
kube-batch 调度器介绍
kube-batch是一个为kubernetes实现批量任务调度的一个调度器,主要用于机器学习,大数据,HPC等场景。
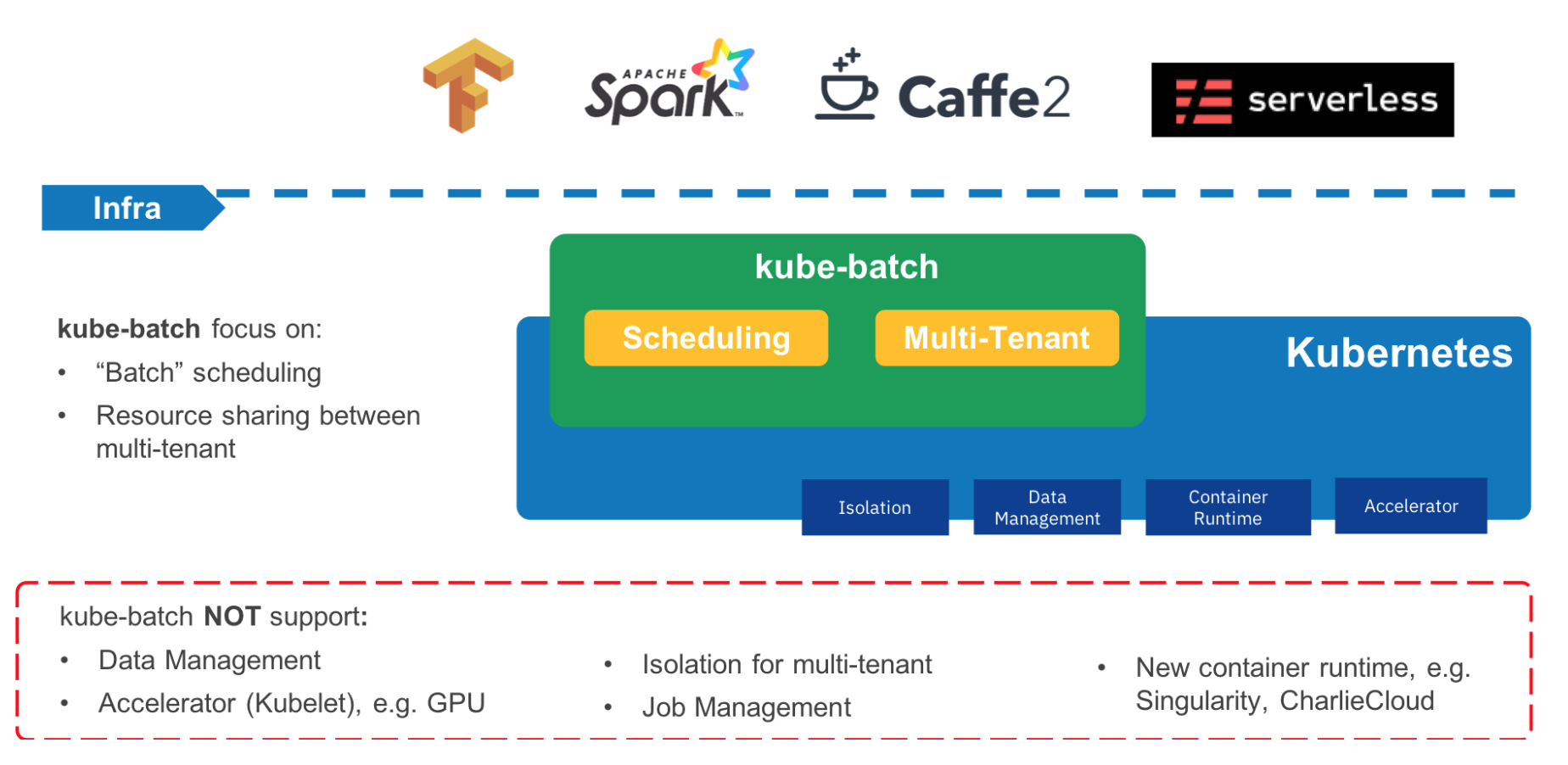
为了使用gang-scheduling,需要在kubernetes集群提前安装kube-batch调度器。具体的安装步骤查看官方教程: kube-batch install
安装完成kube-batch并且测试没有问题,便可以在基于Kubeflow的分布式训练中指定该调度器(kube-batch)。
注意:
1 | Take tf-operator for example, enable gang-scheduling in tf-operator by setting true to --enable-gang-scheduling flag. |
好了,所有的准备工作做完之后,可以使用kube-batch去调度一个任务,为了让任务使用kube-batch,还需要在yaml文件中指定schedulerName参数为kube-batch。下面是详细的例子:
1 | apiVersion: "kubeflow.org/v1beta1" |
总结
在设计AI Paas平台时,除了功能跑起来只是一个开始,在测试过程中随之而来的,网络,存储,调度等等用影响性能的问题,都需要花费大量的精力去解决,基于kube-batch便可以基本解决在调度过程中,kubernetes默认调度器的不足,来达到all or nothing的目的。