MXNet结合kubeflow进行分布式训练
MXnet:是灵活且高效的深度学习库。
MXNet以数据并行的方式进行单机多卡训练
MXNet 支持在多CPU和GPU上进行训练。其中,这些CPU和GPU可以分布在不同的服务器上。
如何使用
注意: 为了使用GPU进行训练任务,需要在编译MXNet中支持GPU。比如: 在配置文件config.mk中设置USE_CUDA=1,然后进行make操作。 详情:http://mxnet.incubator.apache.org/install/
一台GPU机器上的每块GPU都有自己的编号(编号从0开始计数)。如果想使用某一块特定的GPU卡,即可以在代码中直接指定context(ctx); 也可以在命令行中传递参数--gpus。
例如: 如果想在python中使用GPU 0和GPU 2,可以使用下面的代码创建网络模型。
1 | import mxnet as mx |
如果程序接受参数--gpus, 比如: https://github.com/apache/incubator-mxnet/tree/master/example/image-classification, 那么可以尝试下面的代码:
1 | python train_mnist.py --gpus 0,2 |
高级用法
如果多个GPU的计算能力不同,那么可以根据它们的计算性能来划分工作负载。比如,如果GPU 0 是 GPU 2 性能的3倍,那么可以提供一个额外的负载选项 work_load_list=[3, 1]。
如果所有其它超参都相同,在多个GPU上训练结果应该和单GPU上的训练结果相同。但在实际应用中,由于随机存取(随机顺序或其它augmentations),使用不同的种子初始化权重和CuDNN,结果可能不同。
我们可以控制梯度聚合和模型更新(如执行,训练过程)的位置,通过创建不同的KVStore(数据通信模块)。即可以使用mx.kvstore.create(type)来创建一个实例,也可以使用程序的参数--kv-store type来实现功能。
两种常用的功能:
local: 所有的梯度都拷贝到CPU内存完成聚合,同时在CPU内存上完成权值的更新并拷贝回每个GPUworker。这种方式主要在于CPU与GPU,主要的性能负载在于CPU拷贝的负载。device: 梯度聚合和权值更新都在GPU上完成。GPU之间的如果支持Peer to Peer通信(PCIe or NVLink),将避免CPU拷贝的负载,可以大大减轻CPU的负担,仅受限于通信带宽。PCIe 与NVLink通信带宽不同,NVLink具备告诉的Peer to Peer通信带宽。
注意: 如果有大量的GPU(比如: >=4),建议使用device能获取更好的性能。
MXNet以数据并行的方式进行多机多卡训练
在介绍MXNet分布式训练之前,先介绍几个关键性的概念方便理解MXNet的分布式训练:
进程类型
MXNet有三种类型的进程在分布式训练过程中需要相互彼此通讯。
Worker: worker进程会对每一批次(batch_size)的数据样本进行训练。对批数据进行处理之前,workers会从servers服务器pull权重。对批处理数据处理完毕之后workers会聚合梯度数据发送给servers。(如果训练模型的工作负载比较高,建议最好不要把worker和server运行在相同的机器上)。Server: 可以运行多个server服务进程,用于存储模型参数并与worker进行通讯。Scheduler: 一个调度器,在集群中负责调度的角色。主要包含: 等待各个node节点数据的上报数据并让各个node节点知道彼此的存在并互相通讯。
进程之间的关系如下图所示:
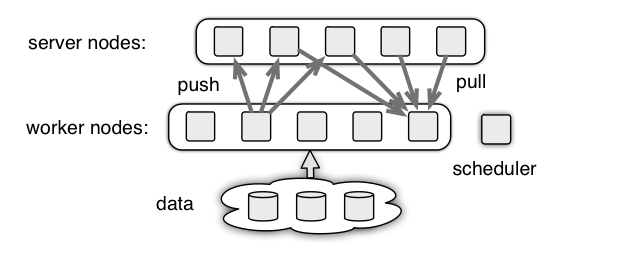
工作流程:
1.worker, server向 scheduler 注册,获取相关的信息。
2.worker 从 server 端pull参数w。
3.worker 基于参数w 和数据计算梯度,然后 push 梯度到 server。
4.server 更新参数w。
5.反复执行 2-4 过程。
KVStore
KVStore是MXNet提供的一个分布式的key-value存储,用来进行数据交换。KVStore本质的实现是基于参数服务器。
- 通过引擎来管理数据一致性,这使得参数服务器的实现变得简单,同时使得KVStore的运算可以无缝的与其他部分结合在一起。
- 使用两层的通讯结构,原理如下图所示。第一层的服务器管理单机内部的多个设备之前的通讯。第二层服务器则管理机器之间通过网络的通讯。第一层的服务器在与第二层通讯前可能合并设备之间的数据来降低网络带宽消费。同时考虑到机器内和外通讯带宽和延时的不同性,可以对其使用不同的一致性模型。例如第一层用强的一致性模型,而第二层则使用弱的一致性模型来减少同步开销。
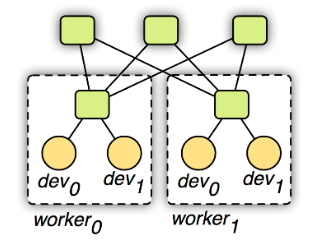
注意: 如果想要在分布式训练中使用KVStore功能,需要在编译MXNet时指定USE_DIST_KVSTORE=1标签用于分布式训练。
通过调用mxnet.kvstore.create()函数并传递dist关键字参数来开启分布式训练的KVStore模式:
1 | kv = mxnet.kvstore.create(‘dist_sync’) |
Refer KVStore API for more information about KVStore.
分布式训练模式
当KVStore被创建并且包含dist关键参数就会开启分布式训练模式。通过使用不同类型的KVStore,可以启用不同的分布式培训模式。具体如下:
dist_sync: 已同步的方式进行分布式训练,在处理每批次(batch)的数据时,所有的workers需要使用相同的模型参数集合。这意味着servers参数服务需要接收来自所有workers模型参数之后,才能进行下一个批次数据的处理。因此在使用这种分布式训练方式时,server参数服务需要等到所有的worker处理完毕之后,并且如果其中的某一个worker异常,会导致整个训练的过程halts。dist_async: 已异步的方式进行分布式训练,server参数服务只要收到worker的计算梯度就会立即更新存储。这意味着哪个worker处理完当前的批次数据,就可以继续下一批次数据的处理。因此该种方式的分布式训练方式比dist_sync要快,但是需要花费更多的epochs去收敛。dist_sync_device: 该分布式训练模式与dist_sync训练模式相同,只是dist_sync_device模式会在多GPUs上进行梯度聚合和更新权重,而dist_sync是在CPU上进行这些操作。这种模式比dist_sync要快,因为GPU和CPU之前的通信,但是会占用更多的GPU显存。dist_async_device: 该模式和dist_sync_device类似,但是是已异步的方式进行的。
开启分布式训练
MXNet为了用户方便的进行分布式训练提供了一个tools/launch.py脚本。
并且支持对多种类型的集群资源进行管理,,如: ssh,mpirun,yarn,sge。
首先clone MXNet的代码到本地:
1 | git clone --recursive https://github.com/apache/incubator-mxnet |
我们使用代码example/gluon/image_classification.py和CIFAR10数据集来对VGG11模型进行分布式训练。
1 | cd example/gluon/ |
上面命令的具体options的解释请查看官方文档:how-to-start-distributed-training
虽然MXNet实现了多机多卡的分布式训练,但是在资源隔离,资源调度,资源限制以及大规模训练时数据共享都是不能满足需求的,所以接下来介绍下MXNet基于Kubeflow的大规模分布式训练。
MXNet结合kubeflow进行分布式训练
准备工作
在将MXNet结合kubeflow进行分布式训练之前,首先需要安装kubeflow环境之前已经介绍了,这里就不在详细说明了。
当kubeflow基础环境部署完成之后,需要针对MXNet安装mxnet-operator。具体安装mxnet-operator的流程如下:
安装mxnet-operator
1
2
3
4
5export KSONNET_APP=/home/wangxigang/kubeflow/kubeflow_ks_app
cd ${KSONNET_APP}
ks pkg install kubeflow/mxnet-job
ks generate mxnet-operator mxnet-operator
ks apply ${ENVIRONMENT} -c mxnet-operator校验MXNet是否安装成功
1
kubectl get crd
输出如下内容代表mxnet-operator安装成功:
1
2
3
4NAME AGE
...
mxjobs.kubeflow.org 4d
...
基于kubeflow测试MXNet分布式训练
准备测试的训练镜像
示例代码: https://github.com/deepinsight/insightface
Dockerfile文件内容:
1
2
3
4
5
6FROM mxnet/python:latest_gpu_mkl_py3
RUN mkdir -p /home/insightface
WORKDIR /home/insightface
ADD insightface .
RUN cd /home/insightface/src
ENTRYPOINT ["python3", "-u", "/home/insightface/src/train_softmax.py"]
创建分布式网络文件系统数据卷(cephfs)
1
2
3
4
5
6
7
8
9
10
11
12apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: insightface-dataset
namespace: demo
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
volumeMode: Filesystem
由于我们是基于kubernetes的pv和pvc的方式使用数据卷,所有集群中需要事先安装好storage-class install,这样当用户创建pvc时,会通过storage-class自动的创建pv。
当创建好pv之后,用户可以将该数据卷mount到自己的开发机上,并将需要训练的数据集移到该数据卷。用于之后创建训练worker pod的时候,挂载到worker容器中,供训练模型使用。
创建mxnet分布式训练任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48apiVersion: "kubeflow.org/v1alpha1"
kind: "MXJob"
metadata:
name: "insightface-train"
namespace: demo
spec:
jobMode: "dist"
replicaSpecs:
- replicas: 1
mxReplicaType: SCHEDULER
PsRootPort: 9000
template:
spec:
containers:
- image: xigang/mxnet-insightface:gpu
name: mxnet
args: ["--data-dir", "/home/data/glintv2_ms1m/glintv2_ms1m/glintv2_ms1m"]
restartPolicy: OnFailure
- replicas: 1
mxReplicaType: SERVER
template:
spec:
containers:
- image: xigang/mxnet-insightface:gpu
name: mxnet
args: ["-u", "/home/data/glintv2_ms1m/glintv2_ms1m/glintv2_ms1m"]
restartPolicy: OnFailure
- replicas: 2
mxReplicaType: WORKER
template:
spec:
containers:
- image: xigang/mxnet-insightface:gpu
name: mxnet
args: ["--network", "m1", "--loss-type", "4", "--margin-m", "0.5", "--data-dir", "/home/data/glintv2_ms1m/glintv2_ms1m/glintv2_ms1m", "--prefix", "../model-r50", "--kv-store", "dist-device-sync", "--gpus","0,1,2,3", "--per-batch-size", "64"]
volumeMounts:
- mountPath: "/home/data/glintv2_ms1m"
name: cephfs-volume
readyOnly: false
resources:
limits:
nvidia.com/gpu: 4
cpu: 20
volumes:
- name: cephfs-volume
persistentVolumeClaim:
claimName: insightface-dataset
restartPolicy: OnFailure创建训练任务
1 | kubectl create -f insightface-train.yaml |
- 查看任务运行情况
1 | # kubectl get mxjobs -n demo |
1 | kubectl get pods -n demo |
- 查看训练日志的信息
登录到具体的node计算节点通过docker logs命令查看训练的日志;
1 | # docker logs -f fc3d73161b27 |
这样就可以通过kubernetes对GPU服务器进行统一的资源管理,并通过kubeflow实现对各种深度学习框架的整合,来实现大规模的分布式训练任务。
总结
虽然已经完成了mxnet结合kubeflow实现大规模的分布式训练,但是除了功能上的基本跑通,还存在很多因素影响分布式训练的性能,如: GPU服务器的网络带宽,普通的我们使用的以太网因为通信延迟的原因,会大大影响多机扩展性。InfiniBand(IB)网络和RoCE网络因为支持RDMA,大大降低了通信延迟,相比之下,20G的以太网格延迟会大大提升。当然,对于现有的普通以太网络,也可以通过别的方法优化通信带宽的减少,比方说梯度压缩。通过梯度压缩,减少通信带宽消耗的同时,保证收敛速度和精度不会有明显下降。MXNet官方提供了梯度压缩算法,按照官方数据,最佳的时候可以达到两倍的训练速度提升,同时收敛速度和精度的下降不会超过百分之一。还有如果使用分布式网络文件系统进行数据集的存储,如果解决吞吐量和网络延迟的问题。以及本地磁盘是否是SSD,还是在训练时是否需要对大文件的数据集进行record.io文件格式的处理及训练前数据集的切分等等问题,都需要更进一步的处理。
参考
- https://mxnet.incubator.apache.org/faq/distributed_training.html#how-to-start-distributed-training
- https://mxnet.apache.org/tutorials/vision/large_scale_classification.html
- https://www.kubeflow.org/docs/guides/components/mxnet/
- https://github.com/apache/incubator-mxnet
- https://github.com/apache/incubator-mxnet/issues/797
- https://transwarpio.github.io/teaching_ml/2016/07/05/mxnet/