基于Kubernetes容器云日志采集与处理实践
大家好,我是来自奇虎360运维开发团队的王希刚。在团队中主要负责容器服务相关的一些开发工作。今天主要跟大家分享一下360容器服务在日志实践方面的一些工作。
首先简单的介绍下360HULK云平台的基本服务组成。包括LVS负载均衡,容器服务,S3/Ceph存储,消息队列等一系列服务。具体如下图所示:
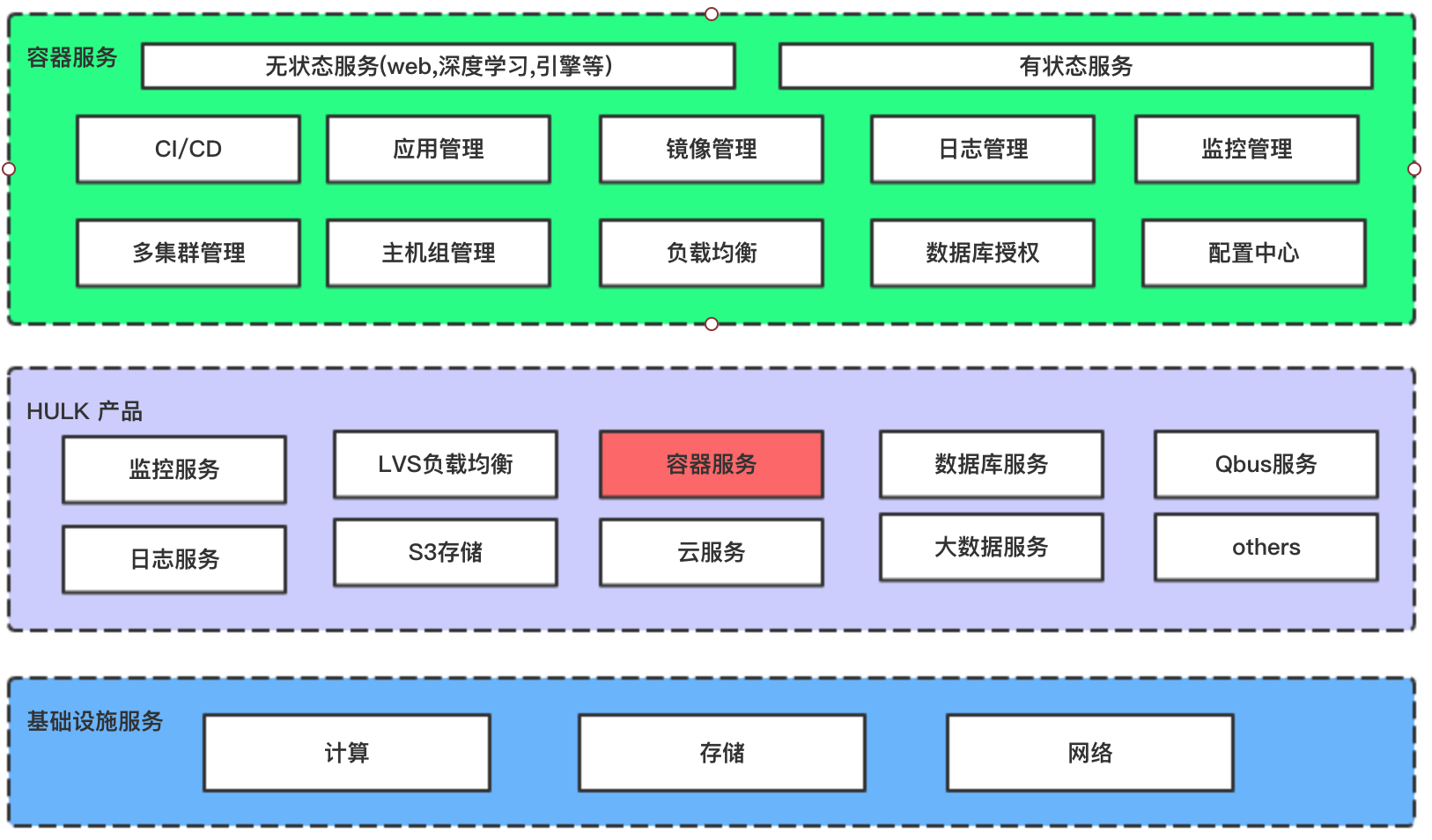
HULK云平台为公司90%以上的业务提供基础服务。其中容器服务就是HULK云平台的一个产品,本次主要和大家分享下容器云在日志收集方面的一些实践。
先介绍下容器日志收集的一些难点。
## 日志采集难点
这里主要从两个方面来讲,第一个是容器本身的特性,第二个是现有采集工具的一些缺陷。
### 容器本身特点导致的问题
容器本身的特点就是太多的不确定性,并且在弹性扩缩容的时候,你无法确定你的Pod调度到哪一个具体的计算节点,导致我们无法事先配置好日志收集路径。下面详细的介绍下容器本身的特性所带来的问题。
1.容器的采集目标多
容器一般将日志写到标准输出,对于容器的标准输出日志,docker engine本身就提供了一个很好的日志采集能力,但是对于多数应用服务来说,都是直接将日志写到本地数据盘,如果应用服务运行在容器中,如何对容器中运行的应用服务进行日志收集?
2.容器的弹性扩缩容特性
由于我们使用kubernetes来对容器进行编排管理,在进行Pod的伸缩扩容时,我们无法事先给日志采集工具配置好应用服务日志的具体采集路径等配置信息,因此这对容器的日志采集来说也是一个问题。
### 现有采集工具缺陷
1.缺乏动态感知配置变化的能力
传统的日志采集工具都需要在业务部署完成之后,手动的配置好日志采集方式和日志路径等信息,由于它无法感知到容器的生命周期变化及动态漂移,所以没有办法动态的获取应用服务的日志配置信息。
2.日志采集数据丢失
这个和容器的特性也有着一定的关系,当Pod异常销毁之后,需要收集的日志文件不会固定存在node磁盘上,只会临时存放,当Pod异常销毁时日志文件也会被删除,采集工具能否将被删除日志文件的内容全部收集走,而不会照成日志文件被删除而收集工具没有收集完日志导致数据丢失的情况。
3.未明确标记日志源
由于一个应用可能由多个运行着相同服务实例的Pod构成,那么当我们将所有的应用服务日志收集到后端存储(如Elasticsearch或HDFS等)时,在搜索日志的时候,无法准确的定位到哪一个应用的哪一个Pod实例异常了。这样就很难定位问题。
针对上面说明的这些在容器中进行日志采集的难点问题,下面介绍下我们是如何解决这些问题的。
## 解决日志采集难点
### 容器本身特点导致的问题
对于上面说的容器本身采集目标多,弹性扩缩容的问题,我们自研了一个叫做log-controller的服务。该服务的主要功能如下:
1. 动态感知kubernetes集群Node和Pod资源的变化,动态生成每个Node节点需要收集日志的配置信息。
2. 定期全量扫描Node节点的Pod信息并生成需要收集日志的配置信息,保持最终数据的一致性。
下面是我们容器中对于标准输出和应用服务日志收集路径的一个规划:
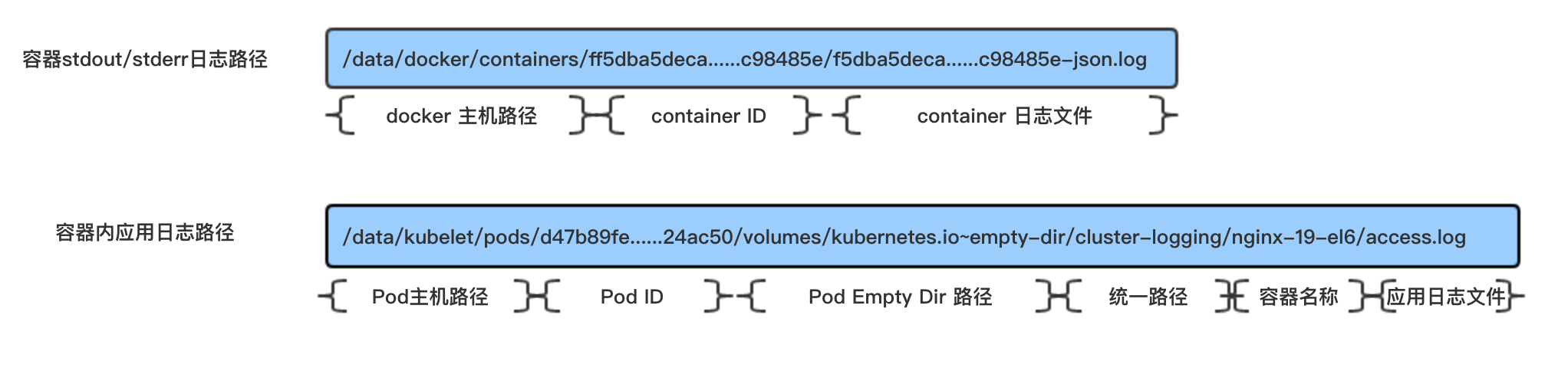
- 容器标准输出/标准错误日志路径
docker engine会将所有容器的标准输出和标准错误日志落盘到Node节点的/data/docker/containers/路径,该路径中包含容器的元数据和日志文件,内容如下:

我们主要负责收集该目录下标准输出日志即可。
容器内应用日志
我们使用kubernetes提供的empty-dir卷,将容器内应用的日志挂载到Node节点,具体的采集路径如下图所示:

log-controller会动态的感知Pod的变化,并对每一个计算节点上的Pod针对这些日志路径,进行日志收集工具(logstash)的配置组装。这样日志收集工具便可以获取每个计算节点它们自己的配置信息,进行容器日志的收集工作。
现有采集工具缺陷
对于现有的日志收集工具存在的缺陷,我们针对这些缺陷的具体解决方案是:
- 缺乏动态感知配置变化的能力
log-controller动态感知Pod的变化,并为其生成相应的日志收集(logstash)配置,推送到我们的配置中心(Qconf),每个计算节点的logstash会周期性的从配置中心(Qconf)拉取最新的配置并进行配置热加载对容器的日志进行收集。
- 日志采集丢失问题
我们以DaemonSet的方式部署logstash日志收集组件到kubernetes集群的所有Node上,logstash本身有一个句柄保持的(close_older)的功能,默认时间是(3600s)。来帮助我们在Pod异常容器被删除的情况下,也能将与该容器关联的日志文件全部收集走。保存容器内部的日志不丢失。
- 未明确标记日志源
logstash允许用户自定义收集日志前缀(custome_msg_prefix)。log-controller在生成日志收集组件需要的配置时,会对custome_msg_prefix进行默认设置。下图显示的是将一条日志记录增加前缀的样式:
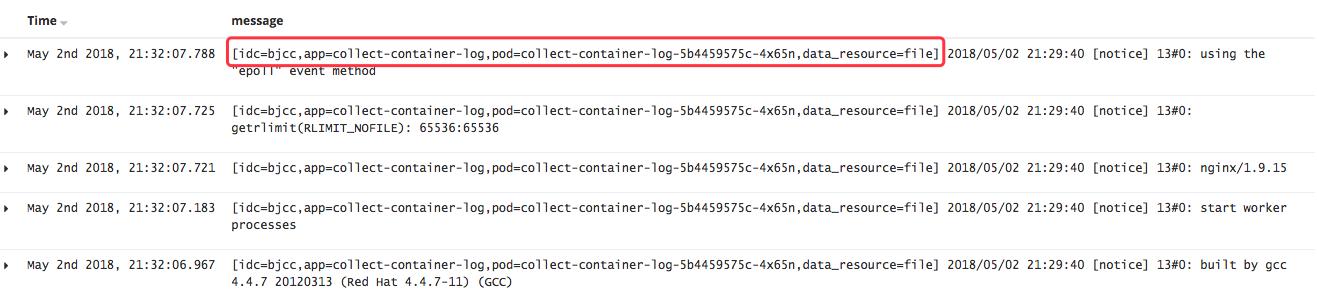
用户也可以在容器服务产品端自定义自己需要的日志前缀或把前缀功能关掉。
通过上面的介绍就已经把容器在日志收集所面临的问题一一的解决了。接下来将介绍现在我们容器日志收集的整体架构。
## 容器云日志收集实践
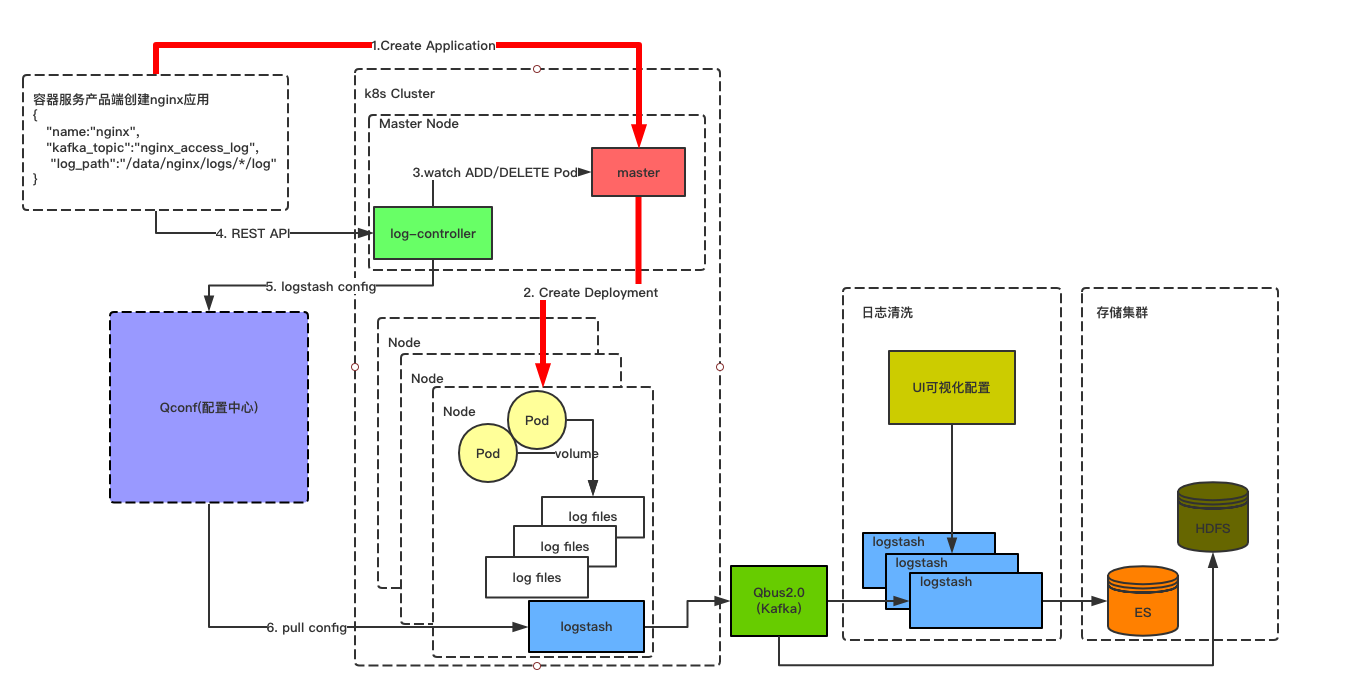
首先来看下我们容器云日志收集的架构图,如下图所示:
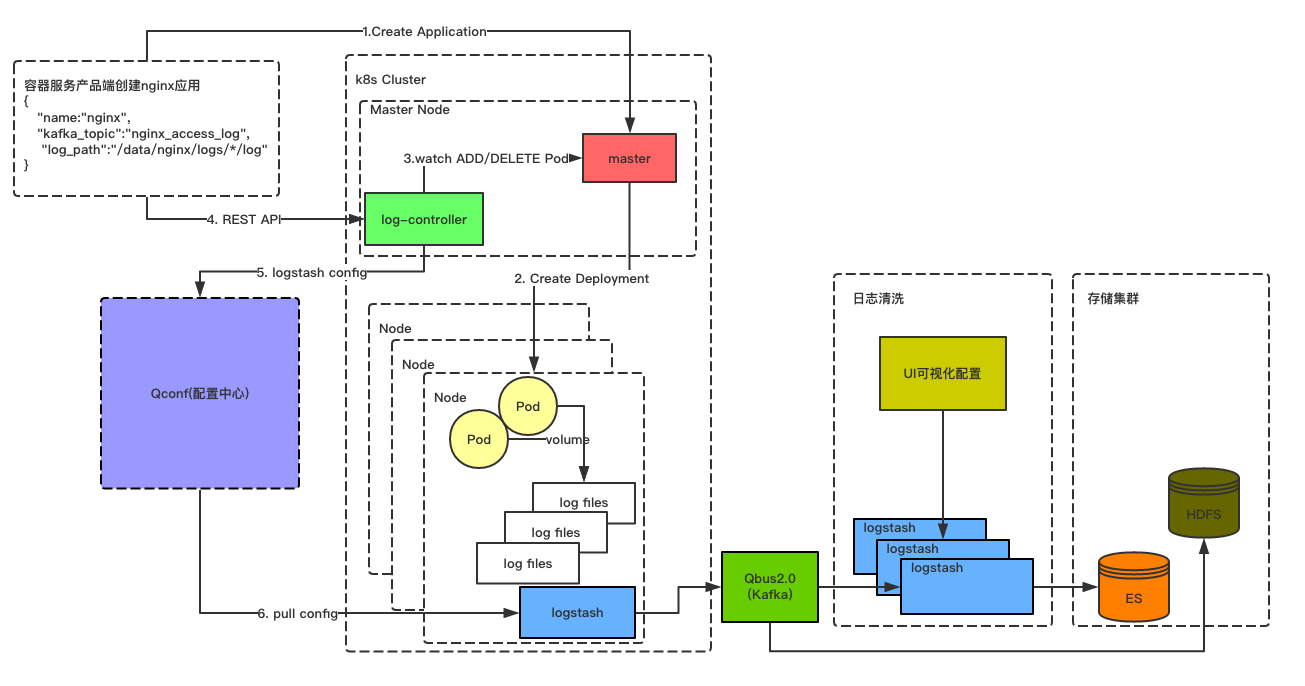
上面这张图就是整个容器云日志收集的架构图。
名词解释:
1. master: kubernetes集群控制节点组件(包含:kube-apiserver,kube-controller-manager,kube-scheduler等)
2. log-controller: 自研的一个动态感知Pod变化的组件。具体的功能上文已经描述。
3. Qconf: 公司自研的服务发现配置中心。
4. Logstash: 日志收集agent,已daemonset的形式部署到kubernetes集群的每一个计算节点上,用于容器的日志收集。
5. Qbus2.0: 公司基于Kafka自研的一个消息队列产品。
6. Elasticsearch: 一个实时分布式搜索和分析引擎,用于对收集的日志进行存储。
7. HDFS: 一个分布式文件系统,用于对收集的日志进行存储。
接下来在该图的基础上给大家介绍下整个容器日志的收集流程。
首先用户需要在容器服务产品端创建一个应用(如:nginx)并指定该应用Pod的副本数。在指定Pod副本数的同时需要指定Pod内部容器是否需要进行日志收集工作。如果需要则去Qbus2.0申请topic。并与指定的容器进行关联,用于后续对该容器进行日志收集处理。
当需要创建应用的所有准备工作处理完成之后,会将该配置已一个deployment的资源去请求master。master收到创建应用的请求之后,会将应用Pod的副本数调度到符合条件的Node上去。如下图所示:
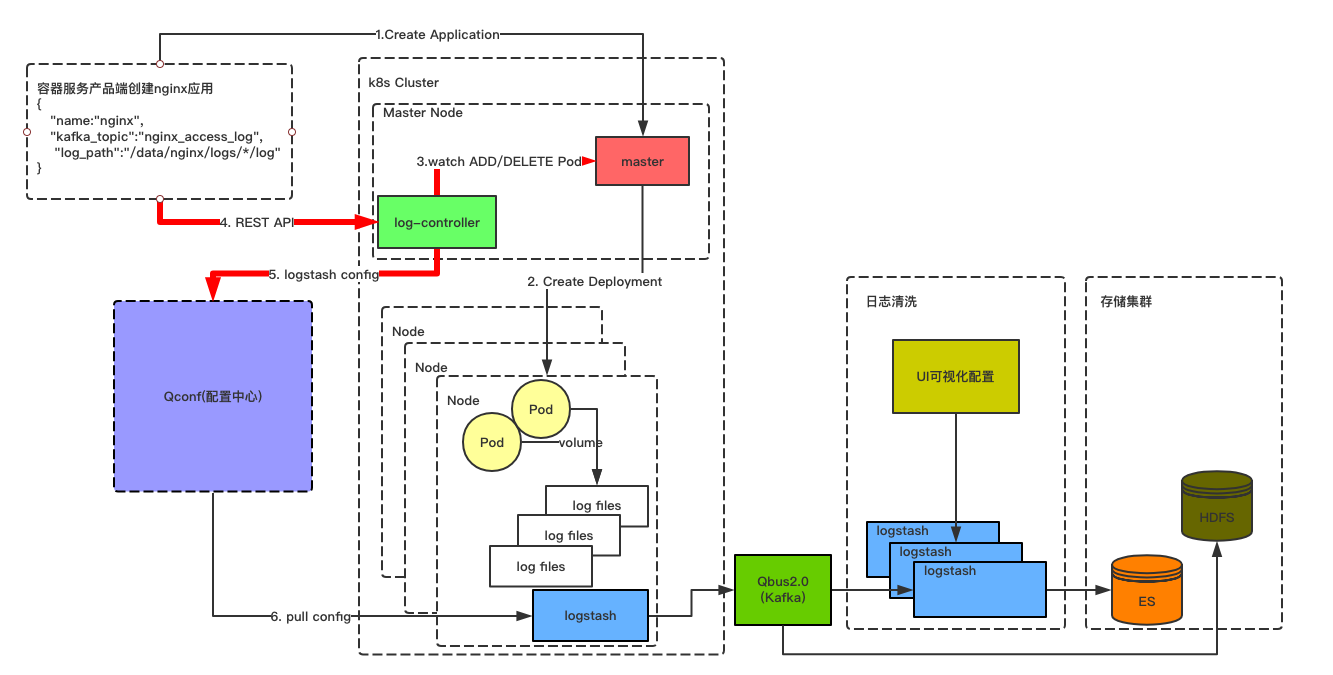
于此同时log-controller会立刻感知到Pod的创建动作,则会去容器服务产品端获取与该应用关联的topic和应用服务日志路径。并在log-controller的逻辑处理层,封装好每个Node节点部署的logstash需要的配置文件。并将配置文件推送到Qconf配置中心。如下图所示:
下面是一个计算节点在Qconf上配置文件的内容:

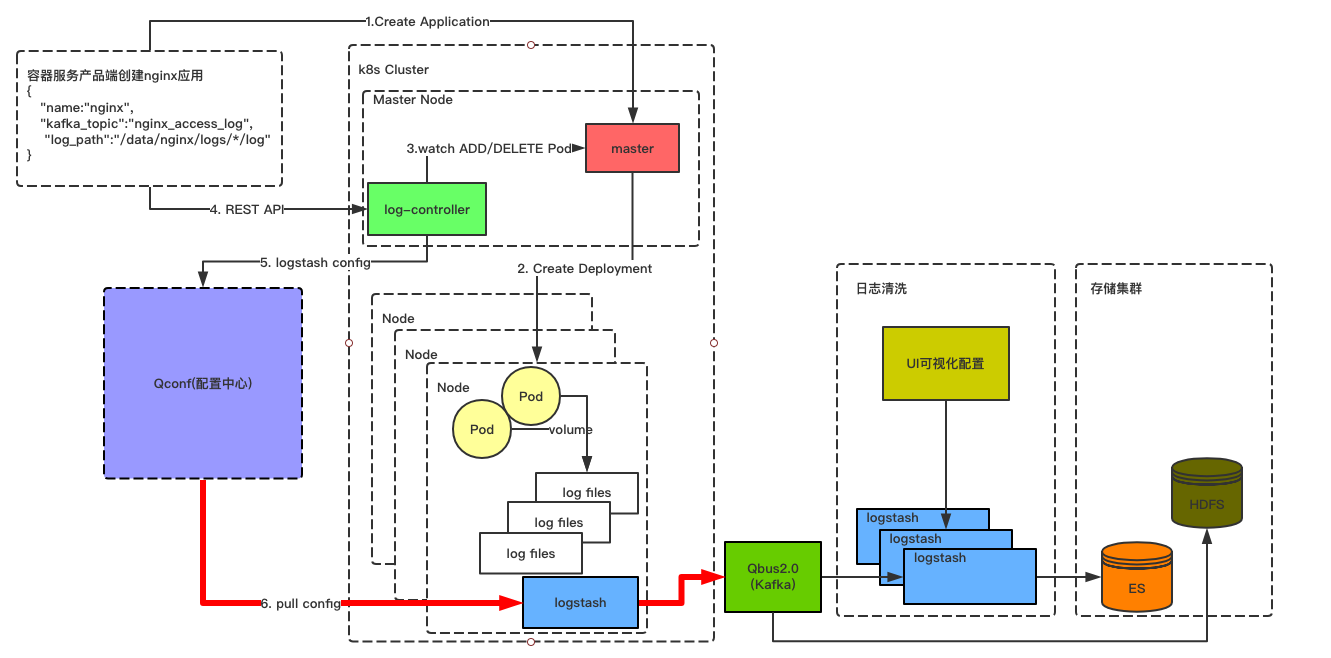
部署到kubernetes集群所有Node节点的logstash会周期性(默认30s)的从Qconf配置中心拉取该Node上最新的配置文件,并自动的对配置文件进行热加载。用来收集该Node上最新的容器日志数据。logstash将收集的日志推送的Qbus2.0消息队列中。如下图所示:
在Qbus2.0消息队列中的数据有两种处理方式:
- 不做任何处理,直接从消息队列将数据入到HDFS文件系统中。
- 将消息队列中的数据进行一层数据清洗之后,入到Elasticsearch集群中。
对于第一种方式,我这里就不详细的描述了,主要描述下第二种消息处理方式:
在日志清洗界面用户可以根据自己的需求启动多个logstash实例进行从Qbus2.0消息队列中对数据进行处理。
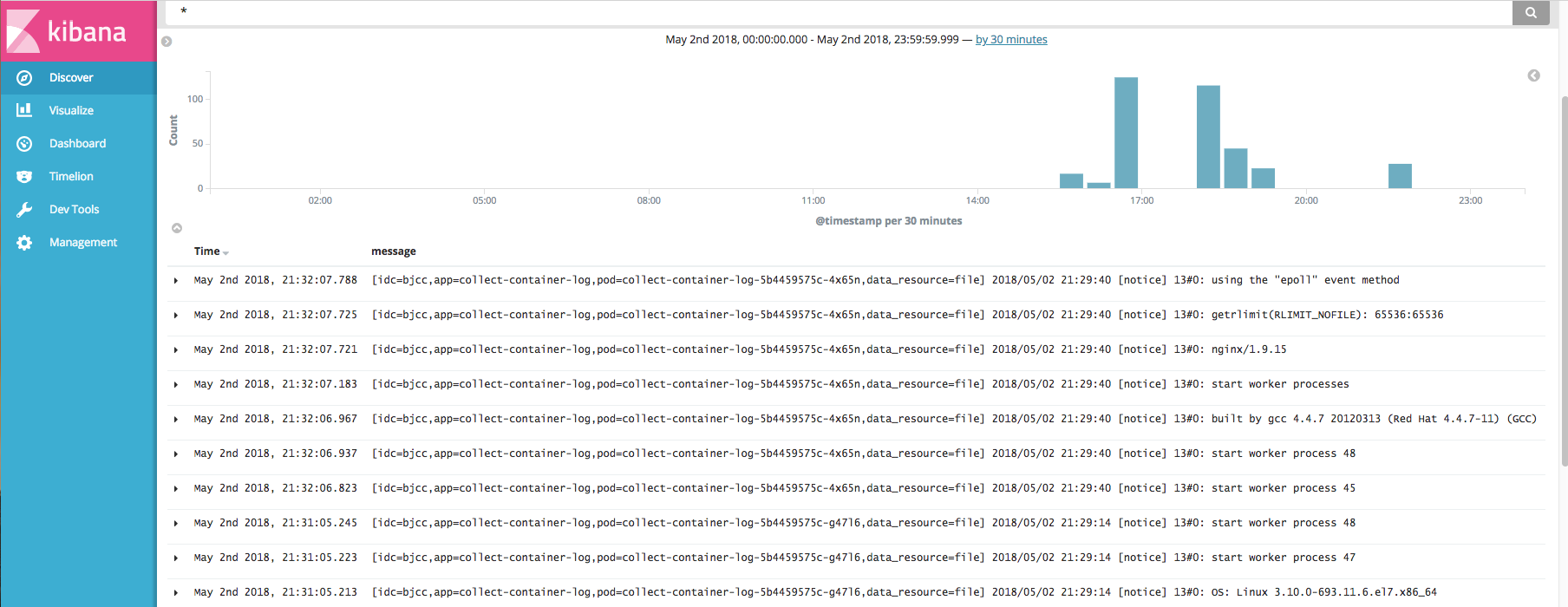
而这些logstash实例我们是以deploymnet的形式进行部署的,方便用户快速的扩缩容logstash实例的数量。并在UI可视化界面配置用户关心的清洗规则。最终将清洗完成的日志存储到Elasticsearch集群中,使用Kibana进行数据检索与展示。Kibana的展示页面如下图所示:
OK, 上面就是容器云整个日志收集架构的整体流程。现在的日志收集只完成了基本的日志收集处理工作,还有很多后期需要完善的工作去处理。
今天的分享就到这里,谢谢大家.