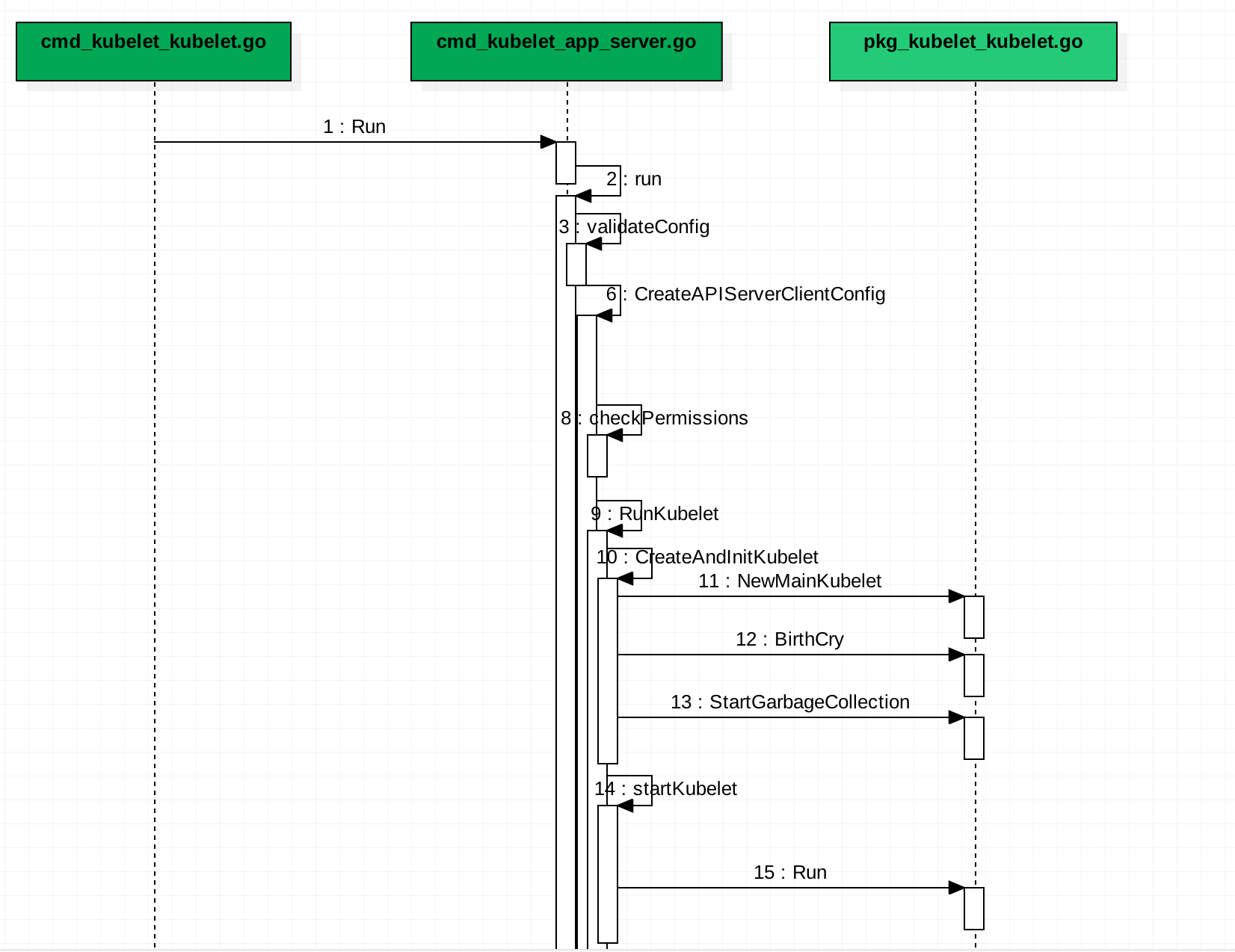
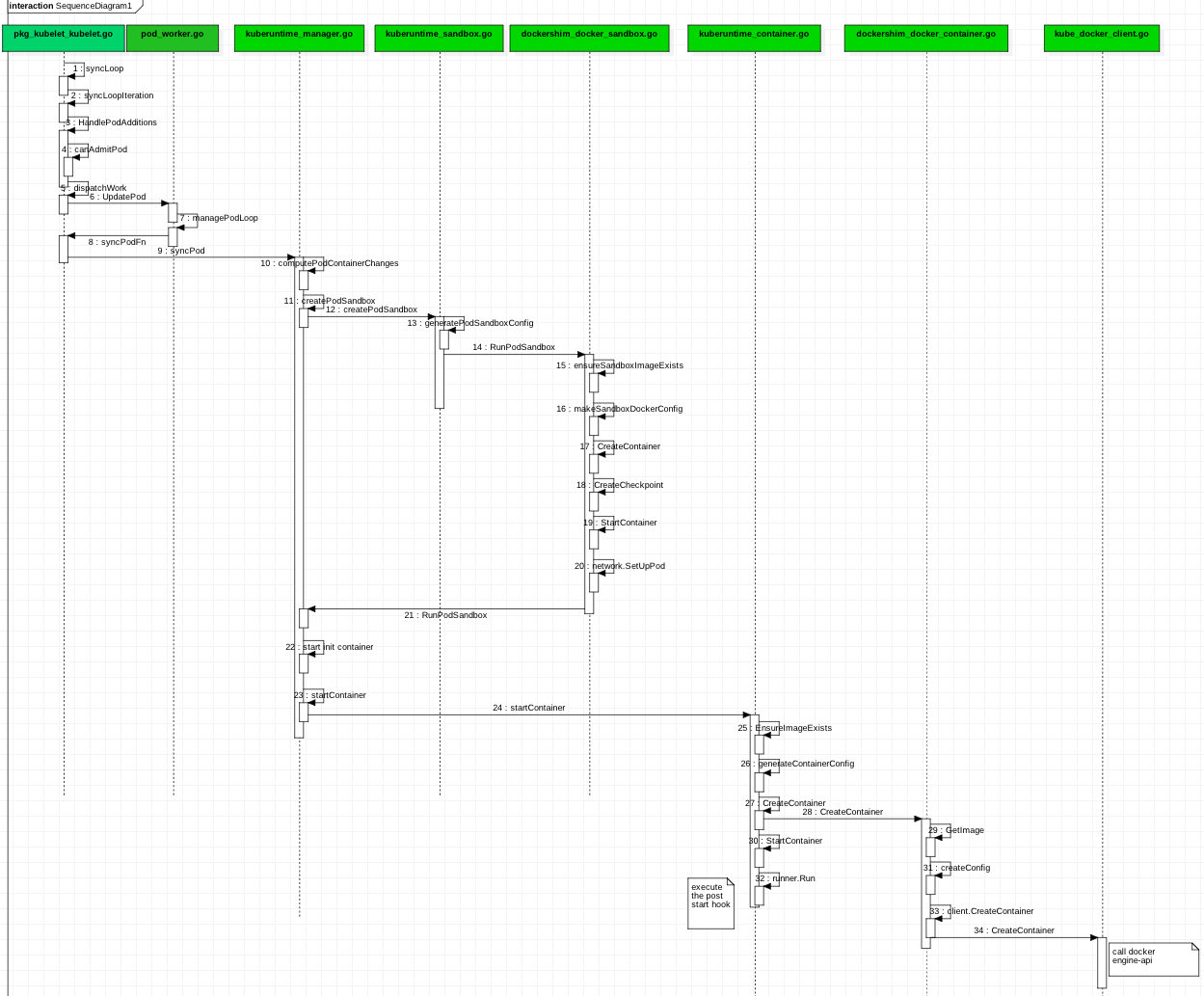
funcCreateAndInitKubelet(kubeCfg *componentconfig.KubeletConfiguration, kubeDeps *kubelet.KubeletDeps, crOptions *options.ContainerRuntimeOptions, standaloneMode bool, hostnameOverride, nodeIP, providerID string)(k kubelet.KubeletBootstrap, err error) { // TODO: block until all sources have delivered at least one update to the channel, or break the sync loop // up into "per source" synchronizations
// Run starts the kubelet reacting to config updates func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) { if kl.logServer == nil { kl.logServer = http.StripPrefix("/logs/", http.FileServer(http.Dir("/var/log/"))) } if kl.kubeClient == nil { glog.Warning("No api server defined - no node status update will be sent.") }
// Start volume manager go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)
if kl.kubeClient != nil { // Start syncing node status immediately, this may set up things the runtime needs to run. go wait.Until(kl.syncNodeStatus, kl.nodeStatusUpdateFrequency, wait.NeverStop) } go wait.Until(kl.syncNetworkStatus, 30*time.Second, wait.NeverStop) go wait.Until(kl.updateRuntimeUp, 5*time.Second, wait.NeverStop)
// Start loop to sync iptables util rules if kl.makeIPTablesUtilChains { go wait.Until(kl.syncNetworkUtil, 1*time.Minute, wait.NeverStop) }
// Start a goroutine responsible for killing pods (that are not properly // handled by pod workers). go wait.Until(kl.podKiller, 1*time.Second, wait.NeverStop)
// Start gorouting responsible for checking limits in resolv.conf if kl.resolverConfig != "" { go wait.Until(func() { kl.checkLimitsForResolvConf() }, 30*time.Second, wait.NeverStop) }
func(kl *Kubelet)syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) { glog.Info("Starting kubelet main sync loop.") // The resyncTicker wakes up kubelet to checks if there are any pod workers // that need to be sync'd. A one-second period is sufficient because the // sync interval is defaulted to 10s. syncTicker := time.NewTicker(time.Second) defer syncTicker.Stop() housekeepingTicker := time.NewTicker(housekeepingPeriod) defer housekeepingTicker.Stop() plegCh := kl.pleg.Watch() for { if rs := kl.runtimeState.runtimeErrors(); len(rs) != 0 { glog.Infof("skipping pod synchronization - %v", rs) time.Sleep(5 * time.Second) continue }