Kube-Scheduler源码解析
源码为kubernetes1.9, git commit id为 925c127ec6b946659ad0fd596fa959be43f0cc05。本文前半部分讲解scheduler的原理,后半部分对scheduler源码进行分析。
kubernetes scheduler基本原理
kubernetes scheduler作为一个单独的进程部署在master节点上,它会watch kube-apiserver进程去发现PodSpec.NodeName为空的Pod,然后根据指定的算法将Pod调度到合适的Node上,这一过程也叫绑定(Bind)。scheduler的输入是需要被调度的Pod和Node的信息,输出是经过调度算法筛选出条件最优的Node,并将该Pod绑定到这个Node上。如下图所示:
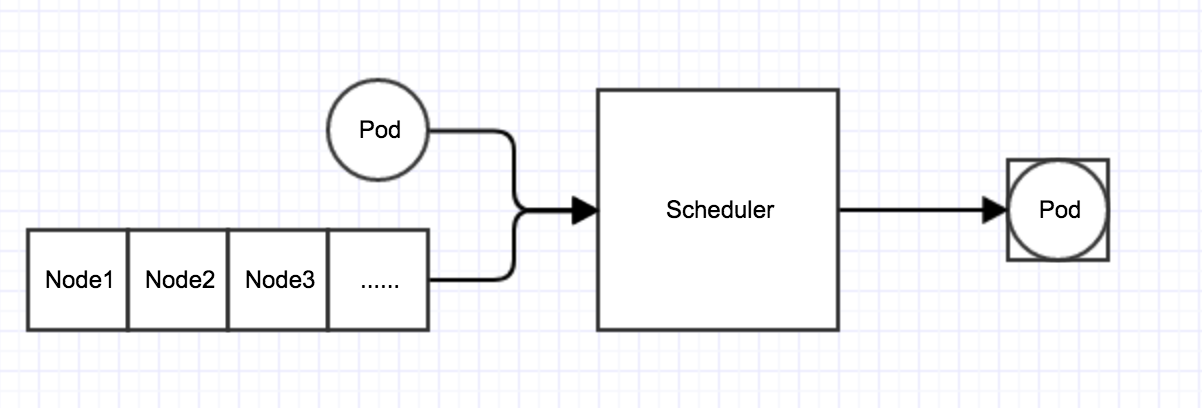
scheduler调度算法分为两个阶段:
预选(Predicates)
根据Predicates策略去滤掉不符合Policies的Node.
优选(Priorities)
经过Predicates剩下的Node,需要经过Priorities策略选出一个最优的Node,并将Pod绑定到该Node上。
根据下面这张调度图详细描述下:
1.首先scheduler根据predicates集合过滤掉不符合的Node。例如,如果PodSpec指定的请求资源(resource requests),那么scheduler会过滤掉没有足够资源的Node。
2.其次scheduler会根据priority functions集合从predicates中过滤出来的Node中,选出一个最优的Node。
算法实现:对每一个Node,priority functions会计算出一个0-10之间的数字,表示Pod放到该Node的合适程度,其中10表示非常合适,0表示不合适,priority functions集合中的每一个函数都有一个权重(weight),最终的值为weight和priority functions的乘积,而一个节点的weight就是所有priority functions结果的加和。例如,有两个priority functions:priorityFunc1和priorityFunc2,对应的weight分别为weight1和weight2,那么NodeA的最终得分是:
1 | finalScoreNodeA = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) |
3.最终,得分最高的Node胜出(如果有多个得分相同的Node,会随机的选取一个Node作为最终胜出的Node)。

kubernetes scheduler源码分析
scheduler的代码结构
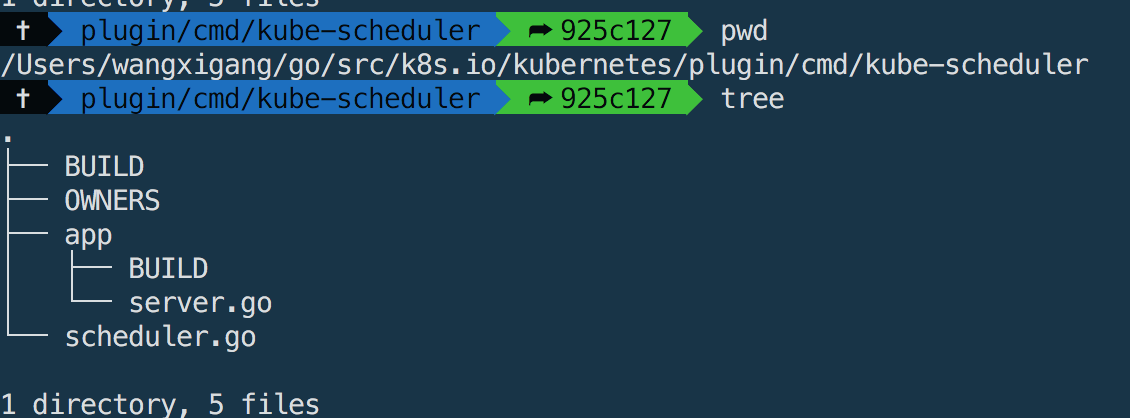
- k8s.io/kubernetes/plugin/cmd/scheduler.go 为程序入口文件(main.go)
- k8s.io/kubernetes/plugin/cmd/kube-scheduler/app/server.go 包含scheduler的基础配置项
除了入口函数,scheduler的具体逻辑实现均在k8s.io/kubernetes/plugin/pkg/scheduler目录下,这里就不一一介绍了。
scheduler的具体实现
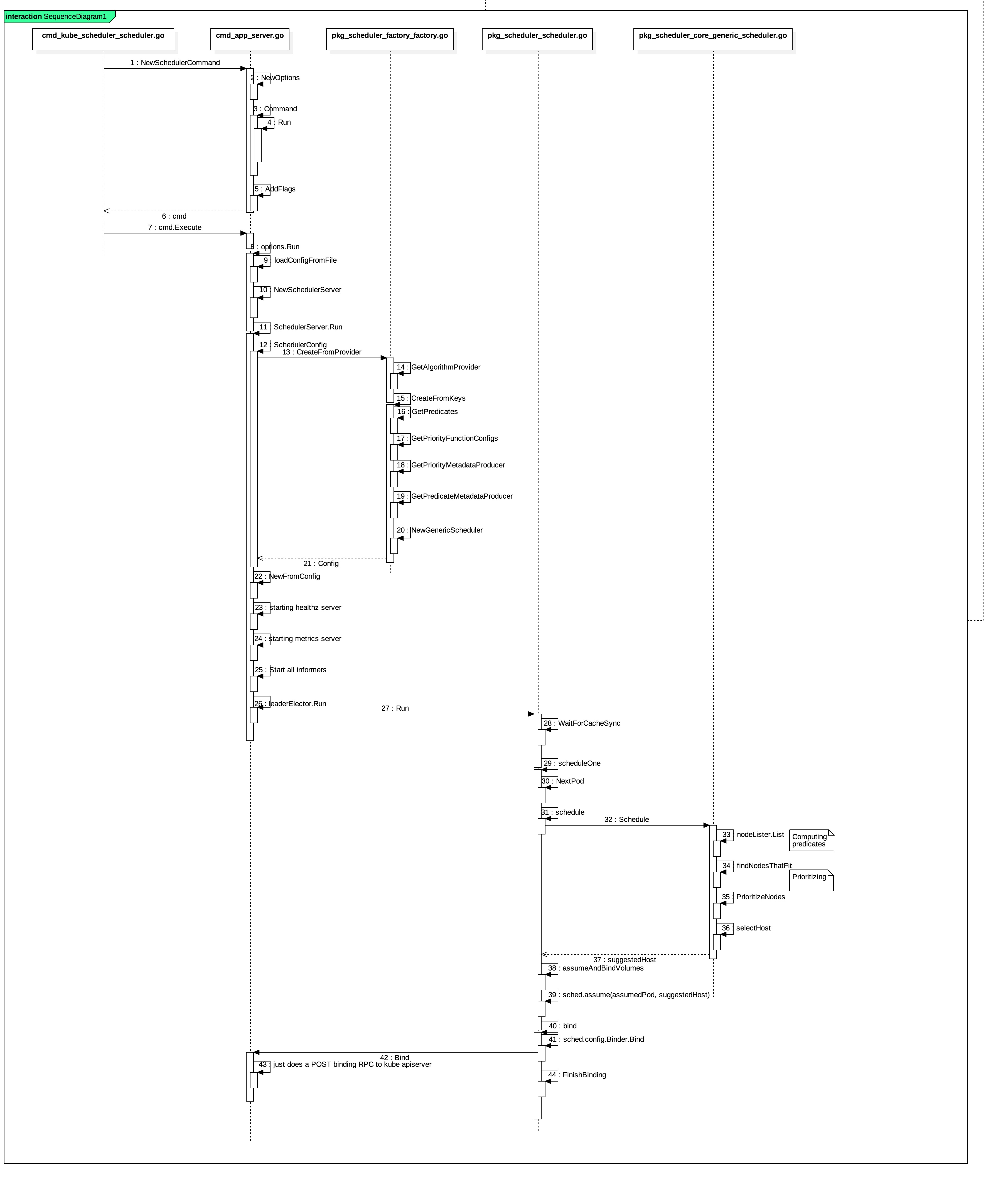
上面的时序图就是整个scheduler的具体实现逻辑。下面根据这个时序图来对scheduler的源码进行解析。
- NewSchedulerCommand 创建一个scheduler命令行实例,用来对scheduler的命令行参数进行解析校验并且包含scheduler程序的入口函数
Run的函数定义。 - command.Execute() 会执行命令行实例中的
options.Run方法。
在options.Run中主要进行了如下的操作:
- loadConfigFromFile 加载scheduler配置文件信息。
NewSchedulerServer 创建scheduler server实例,使用scheduler配置参数对scheduler server进行初始化,如:
- createClients 创建一系列client,如连接k8s的client,进行scheduler选主的client及event client.
- makeLeaderElectionConfig 生成
Leader Election配置信息(scheduler做了HA,可以同时运行多个实例进程,但只有一个能正常工作,如果主的scheduler挂了,会重新进行选举)。 - makeHealthzServer 初始化healthz server,用于健康检查。
- makeMetricsServer 初始化metrics server,用于prometheus性能监控。
SchedulerServer.Run 启动SchedulerServer,用于监控还是否有Pod待调度,并且进行相应的调度工作。具体的代码实现:
1 | func (s *SchedulerServer) Run(stop chan struct{}) error { |
- SchedulerConfig()创建Scheduler Config,其中关键性函数是
NewConfigFactory和CreateFromProvider。- NewConfigFactory 定义了podQueue用来存储需要被调度的Pod,每当新的Pod建立后,就会将Pod添加到该queue中。
- CreateFromProvider 根据algorithm provider名称创建一个scheduler配置信息。其中
GetAlgorithmProvider则根据provider名称去获取指定的provider。
1 | func (f *configFactory) CreateFromProvider(providerName string)(*scheduler.Config, error) { |
scheduler默认使用的provider是DefaultProvider。它主要实现了如下数据结构:
1 | type AlgorithmProviderConfig struct { |
AlgorithmProviderConfig这个数据结构包含预选和优选相关算法key的集合(一个算法对应一个key, key是算法的名字,value是算法的具体实现funtion),而这些算法注册是在https://github.com/kubernetes/kubernetes/blob/release-1.9/plugin/pkg/scheduler/algorithmprovider/defaults/defaults.go文件的init()方法中进行注册(实现使用的是工厂模式)。
如果想了解预选和优选算法的详细信息,请参看官方文档:https://github.com/kubernetes/community/blob/master/contributors/devel/scheduler_algorithm.md
接着往下说: 通过GetAlgorithmProvider得到了provider关联的预选和优选算法集合的Key。然后通过调用CreateFromKeys(预选和优选的Key作为参数)来获取预选和优选算法的具体实现(funtion),并对NewGenericScheduler实例进行初始化,返回最终的scheduler配置信息。
- NewFromConfig 由Scheduler Config创建一个schduler。
- Start up the healthz server 启动健康检查服务
- Start up the metrics server 启动metrics服务,供prometheus进行性能监控数据的抓取。
- LeaderElection 如果指定选举的方式来启动scheduler,则使用这种方式来执行scheduler。(使用CallBack的方式执行Run方法。如果主的scheduler出现问题,还会指定优雅处理函数对其进行处理)。
下面就到了scheduler真正干活的逻辑了,每次调度一个Pod都会执行下面的Scheduler.Run(),具体的代码如下:
1 | func (sched *Scheduler) Run() { |
- WaitForCacheSync() 将最新的数据同步到SchedulerCache缓存中。
- scheduleOne() 调度Pod的整体逻辑。具体的实现可以看下面代码:
1 | func (sched *Scheduler) scheduleOne() { |
- NextPod() 从PodQueue中获取一个未绑定的Pod。
- schedule(pod) 执行对应Algorithm的Schedule,进行预选和优选。接口定义如下:
1 | // ScheduleAlgorithm is an interface implemented by things that know how to schedule pods |
- Schedule 主要包含如下几个重要的方法:
- nodeLister.List() 获取可用的Node列表。
- findNodesThatFit()进行预选。
- PrioritizeNodes() 进行优选。
- selectHost() 如果优选出的多个得分相同的Node,则随机选取一个Node。
- assume() 更新SchedulerCache中Pod的状态,标志该Pod为scheduled,并更新到NodeInfo中。
- bind() 调用kube-apiserver API,将Pod绑定到选出的Node,之后Kube-apiserver会将元数据写入etcd中。接口定义如下:
1 | // Binder knows how to write a binding. |
这样一个Pod绑定到Node的流程就完成了。
总结
kube-scheduler作为kubernetes master上一个单独的进程提供调度服务,通过–master指定kube-api-server的地址,用来watch Pod和Node并调用api server bind接口完成Node和Pod的Bind操作。
kube-scheduler中维护了一个FIFO类型的PodQueue cache(其实还有一种PriorityQueue用于指定Pod的优先级,需要指定参数开启,默认是FIFO队列),新创建的Pod都会被ConfigFactory watch到,被添加到该PodQueue中,每次调度都从该PodQueue中NextPod()一个即将调度的Pod。
获取到待调度的Pod后,就执行AlgorithmProvider配置Algorithm的Schedule方法进行调度,整个调度过程分两个关键步骤:Predicates和Priorities,最终选出一个最适合该Pod的Node。
更新SchedulerCache中Pod的状态(AssumePod),标志该Pod为scheduled,并更新到NodeInfo中。
调用api server的Bind接口,完成Node和Pod的Bind操作,如果Bind失败,从SchedulerCache中删除上一步中已经Assumed的Pod。