浅谈 Linux Namespace
对于搞云计算的同学,对容器技术大家应该都不会陌生,容器的资源限制使用的底层技术是cgroups并且容器的隔离使用的是Linux Namespace机制。之前的文章简单的介绍了Linux cgroups。通过本篇文章来给大家介绍下Linux Namespace的机制。
Linux namespaces 介绍
namespaces是Linux内核用来隔离内核资源的方式。通过namespaces可以让一些进程只能看到与自己相关的那部分资源。而其它的进程也只能看到与他们自己相关的资源。这两拨进程根本感知不到对方的存在。而它具体的实现细节是通过Linux namespaces来实现的。
总结: Linux namespaces对系统进程进行轻量的虚拟化隔离。
当前Linux内核只支持6中namespaces:
- mnt(mount points, filesystems)
- pid(process)
- net(network stack)
- ipc(System V IPC)
- uts(hostname)
- user(UIDs)
下面是Linux Kernel版本迭代过程中对这6中namespaces的支持情况及对应的flag:
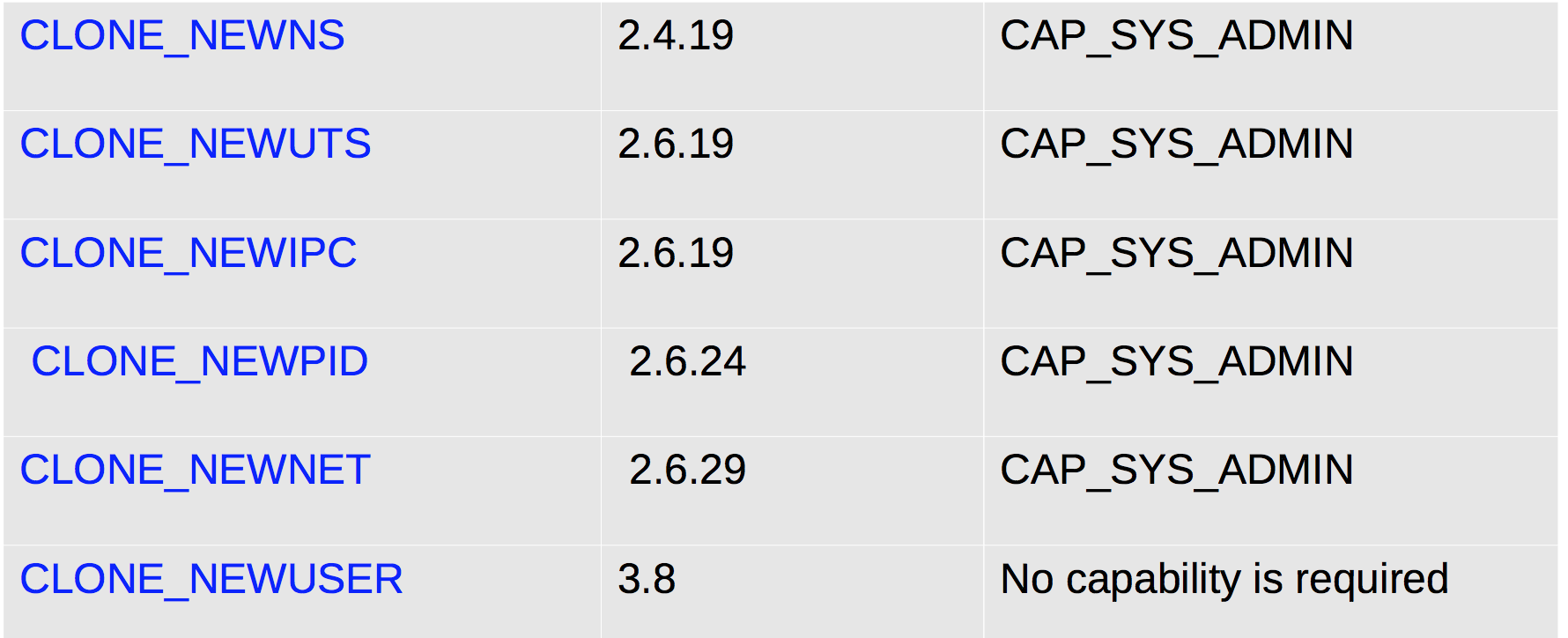
最初打算对Linux内核支持10种namespaces,但是下面的4中没有实现:
- security namespace
- security keys namespaces
- device namespace
- time namespace
接下来先介绍namespace的API,然后在针对Linux内核现在支持的6中namespace分别进行介绍。
Namespaces API 介绍
下面3个系统调用API会被用于namespaces:
- clone(): 用于创建新的进程同时创建新的
namespaces。并且新的进程会被attach到新的namespace里面。
1 | int clone(int (*fn)(void *), void *child_stack, |
- 参数child_func传入子进程运行的程序主函数。
- 参数child_stack传入子进程使用的栈空间
- 参数flags表示使用哪些CLONE_*标志位
- 参数args则可用于传入用户参数
ClONE_NEW* flag有20多被包含在include/linux/sched.h头文件中。
- unshare(): 不会创建新的进程,但是会创建新的namesapce并把当前的进程
attach到该namespace里面。
1 | int unshare(int flags); |
- setns(): 将进程
attach到一个已经存在的namespace里面。
1 | int setns(int fd, int nstype); |
- 参数fd表示我们要加入的namespace的文件描述符。如:/proc/[pid]/ns下面对应的文件描述符。
- 参数nstype让调用者可以去检查fd指向的namespace类型是否符合我们实际的要求。如果填0表示不检查。
UTS Namespace
UTS namespace提供了主机名和域名的隔离,这样每一个容器就可以拥有独立的主机名和域名,在网络上可以被视为一个独立的节点而非宿主机上的一个进程。
下面让我们来看下UTS的隔离效果,测试代码如下:
1 |
|
主要是main中在调用clone函数创建新进程及新namespace的时候,传递了CLONE_NEWUTSflag,用于对主机名和域名的隔离。
编译并运行程序会发现主机名发生了变化。
1 | [root@localhost ~]# gcc -Wall uts.c -o uts && ./uts |
每个容器的主机名不同就是使用UTS Namespace机制实现的。
IPC Namespace
容器中进程间的通信采用的方式包括: 信号量,消息队列和共享内存。与虚拟机不同的是,容器内部进程间通信对宿主机来说,实际上是具有相同的PID namespace中的进程间通信,因此需要一个而唯一的标识符来进行区别。申请IPC资源就申请了这样一个全局唯一的32位ID,所以IPC namespace中实际上包含了系统IPC标识符以及实现POSIX消息队列的文件系统。在同一个IPC namespace下的进程彼此可见,而与其他的IPC namespace下的进程则互相不可见。
下面我们来看下IPC的隔离效果,测试代码如下:
1 |
|
main函数中调用clone函数创建新进程同时创建新namespaces的时候,传递CLONE_NEWIPCflag, 来实现进程间IPC的隔离。
在运行程序的时候,为了方便测试进程间通信是否被真正的隔离了,
1.首先我们先使用ipcmk -Q命令创建一个queue:
1 | [root@locahost ~]# ipcmk -Q |
2.使用ipcs -q查看queue是否创建成功:
1 | [root@localhost ~]# ipcs -q |
3.编译并运行ipc.c代码对IPC进行隔离并进行验证:
1 | [root~]# gcc -Wall ipc.c -o ipc && ./ipc |
从运行的结果来看,已经找不到原先声明的message queue,实现了IPC的隔离。
PID Namespace
PID namespace隔离非常实用,它对进程PID重新标号,即两个不同的namespace下的进程可以拥有同一个PID。每一个PID namespace都有字的计数程序。内核为所有的PID namespace维护了一个树状结构,最顶层的是系统初始时创建的,即root namespace。他创建的新的PID namespace称child namespace。通过这种方式,不同的PID namespace会形成一个等级的体系。所属的父节点可以看到子节点中的进程,并可以通过信号等方式对子节点中的进程产生影响。反过来,子节点不能看到父节点PID namespace中的任何内容。
由此产生如下结论:
- 每个PID namespace中的第一个进程“PID 1“,都会像传统Linux中的init进程一样拥有特权,起特殊作用。
- 一个namespace中的进程,不可能通过kill或ptrace影响父节点或者兄弟节点中的进程,因为其他节点的PID在这个namespace中没有任何意义。
- 如果你在新的PID namespace中重新挂载/proc文件系统,会发现其下只显示同属一个PID namespace中的其他进程。
- 在root namespace中可以看到所有的进程,并且递归包含所有子节点中的进程。
下面我们来看下对PID的隔离效果,测试代码如下:
1 |
|
main函数中调用clone函数创建新的进程同时创建新的namespace的时候,传递CLONE_NEWPID flag。来实现对PIDg隔离。
让我们编译并运行代码,看下效果:
1 | [root ~]# gcc -Wall pid.c -o pid && ./pid |
运行ps aux命令来查看是否实现了PID namespace的隔离;发现还会看到宿主机上的所有的进程。这是由于没有对文件系统进行隔离,ps/top之类的命令调用的是真实系统下的/proc文件内容,看到的自然是所有的进程。
运行下面的mount命令来对/proc 文件系统进行隔离:
1 | [root@changed name ~]# mount -t proc proc /proc |
看到达到了对PID namespace隔离的效果。
Mount Namespace
Mount namespace通过隔离文件系统挂载点对隔离文件系统提供支持。隔离后,不同的mount namespace中的文件结构发生变化也互不影响。你可以通过/proc/[pid]/mounts查看到所有挂载在当前namesapce中的文件系统,还可以通过/proc/[pid]/mountstats看到mount namespace中文件设备的统计信息,包括挂载的文件名称,文件系统类型,挂载位置等等。
进程在创建mount namespace的时候,会把当前结构复制给新的namespace。 新的namespace中的所有mount操作都影响自身的文件系统,而对外界不会产生任何影响。这样做就严格地实现了隔离。
让我们来对文件系统进行隔离,测试的代码如下:
1 |
|
main函数中调用clone函数创建新进程同时创建新的namespace时,需要增加CLONE_NEWNS flag。来实现对Mount namespace的隔离。
下面让我们编译并运行下程序来验证是否实现了对文件系统的隔离。
1 | [root@localhost ~]# gcc -Wall mntns.c -o mnt && ./mnt |
从上面程序执行输出的结果可以看到,已经实现了对文件系统的隔离。关于mount相关的知识很多。这里就具体的详细介绍了,如果感兴趣可以看下:
Mount namespaces and shared subtrees
mount a filesystem
Network Namespace
Net namespace主要提供关于网络资源的隔离,包括网络设备IPv4和IPv6协议栈,IP路由表,防火墙,/proc/net目录,/sys/class/net目录,端口等等。一个物理的网络设备最多存在一个net namespace中,你可以创建veth pair(虚拟网路设备对:有两端如果有数据从一端传入另一端也能收到,反之亦然)在不同的network namespace间创建通道依次达到通信的目的。
一般情况下,物理网络设备都分配在最初的root namespace中,但是如果你有多块物理网卡,也可以把其中一块或多块分配给新创建的network namespace。需要注意的是,当新创建的network namespace被释放时(所有内部的进程都终止并且namespace文件没有被挂载或打开),在这个namespace中的物理网卡会返回到root namespace而非创建该进程的父进程所在的network namespace。
当我们说到network namespace时,其实我们指的未必是真正的网络隔离,而是把网络独立出来,给外部用户一种透明的感觉,仿佛跟另外一个网络实体在进行通信。为了达到这个目的,容器的经典做法就是创建一个veth pair,一端放置在新的namespace中,通常命名为eth0,一端放在原先的namespace中连接物理网络设备,再通过网桥把别的设备连接进来或者进行路由转发,以此网络实现通信的目的。
也许有读者会好奇,在建立起veth pair之前,新旧namespace该如何通信呢?答案是pipe(管道)。我们以Docker Daemon在启动容器dockerinit的过程为例。Docker Daemon在宿主机上负责创建这个veth pair,通过netlink调用,把一端绑定到docker0网桥上,一端连进新建的network namespace进程中。建立的过程中,Docker Daemon和dockerinit就通过pipe进行通信,当Docker Daemon完成veth-pair的创建之前,dockerinit在管道的另一端循环等待,直到管道另一端传来Docker Daemon关于veth设备的信息,并关闭管道。dockerinit才结束等待的过程,并把它的“eth0”启动起来。整个效果类似下图所示。
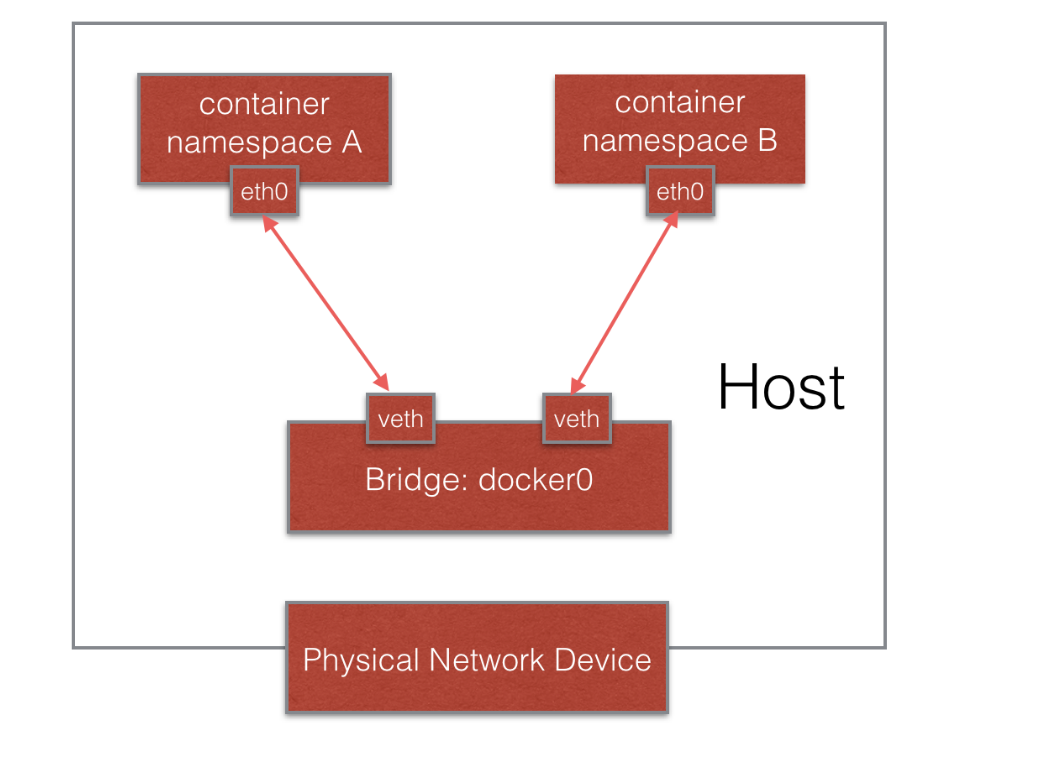
跟其他namespace类似,对network namespace的使用其实就是在创建的时候添加CLONE_NEWNET标识位。也可以通过命令行工具ip创建network namespace。在代码中建立和测试network namespace较为复杂,所以下文主要通过ip命令直观的感受整个network namespace网络建立和配置的过程。
首先我们可以创建一个命名为test_ns的network namespace:
1 | root@localhost ~]# ip netns add test_ns |
当ip命令工具创建一个network namespace时,会默认创建一个回环设备(loopback interface:lo),并在/var/run/netns目录下绑定一个挂载点,这就保证了就算network namespace中没有进程在运行也不会被释放,也给系统管理员对新创建的network namespace进行配置提供了充足的时间。
通过ip netns exec命令可以在新创建的network namespace下运行网络管理命令。
1 | [root@localhost ~]# ip netns exec test_ns ip link list |
上面的命令为我们展示了新建的namespace下可见的网络链接,可以看到状态是DOWN,需要再通过命令去启动。可以看到,此时执行ping命令是无效的。
1 | [root@localhost ~]# ip netns exec test_ns ping 127.0.01 |
启动命令如下,可以看到启动后再测试就可以ping通。
1 | [root@localhost ~]# ip netns exec test_ns ip link set dev lo up |
这样只是启动了本地的回环,要实现与外部namespace进行通信还需要再建一个网络设备对,命令如下。
1 | [root@localhost ~]# ip link add veth0 type veth peer name veth1 |
- 第一条命令创建了一个网络设备对,所有发送到veth0的包veth1也能接收到,反之亦然
- 第二条命令则是把veth1这一端分配到test_ns这个network namespace。
- 第三、第四条命令分别给test_ns内部和外部的网络设备配置IP,veth1的IP为10.1.1.1,veth0的IP为10.1.1.2。
此时两边就可以互相连通了,效果如下。
1 | root@localhost ~]# ping 10.1.1.1 |
删除net namespace:
1 | [root@localhost ~]# ip netns delete test_ns |
User Namespace
注意:User namespace是Linux内核(Linux 3.8)最后支持的namespace,所以有的版本的系统内核可能还没有对该namespace支持。
User namespace主要隔离了安全相关的标识符和属性,包括用户ID,用户组ID,root目录等。通俗点就是: 一个普通用户的进程通过clone()创建新的进程在新user namespace中可以拥有不同的用户和用户组。这意味着一个进程在容器外属于一个没有特殊权限的普通用户,但是它创建的容器进程却属于拥有所有权限的超级用户,这个技术为容器提供了极大的自由。
Linux中,特权用户的user ID是0,演示的最终我们将看到user ID非0的进程启动user namespace后user ID可以变为0。使用user namespace的方法和其它的namespace的使用方式没有太大的区别。即调用clone()的时候,需要加入CLONE_NEWUSER标识位。
让我们来看下user namespace的隔离效果,测试代码如下:
1 |
|
在编译并执行代码之前,我们先来看下当前的用户uid和gid.
1 | id -u |
现在编译并运行我们的代码来验证user namespace是否隔离成功:注意: 如果编译时如下报错:
1 | fatal error: sys/capability.h: No such file or directory |
则在ubuntu编译则需要安装libcap-dev包,如果在centos上编译则需要安装libcap-devel包。
运行的结果如下:
1 | [root@localhost ~]# gcc userns.c -Wall -lcap -o userns && ./userns |
通过验证我们可以得到以下信息。
- user namespace被创建后,第一个进程被赋予了该namespace中的全部权限,这样这个init进程就可以完成所有必要的初始化工作,而不会因权限不足而出现错误。
- 我们看到namespace内部看到的UID和GID已经与外部不同了,默认显示为65534,表示尚未与外部namespace用户映射。我们需要对user namespace内部的这个初始user和其外部namespace某个用户建立映射,这样可以保证当涉及到一些对外部namespace的操作时,系统可以检验其权限(比如发送一个信号或操作某个文件)。同样用户组也要建立映射。
- 还有一点虽然不能从输出中看出来,但是值得注意。用户在新namespace中有全部权限,但是他在创建他的父namespace中不含任何权限。就算调用和创建他的进程有全部权限也是如此。所以哪怕是root用户调用了clone()在user namespace中创建出的新用户在外部也没有任何权限。
- 最后,user namespace的创建其实是一个层层嵌套的树状结构。最上层的根节点就是root namespace,新创建的每个user namespace都有一个父节点user namespace以及零个或多个子节点user namespace,这一点与PID namespace非常相似。
接下来我们就要进行用户绑定操作,通过在/proc/[pid]/uid_map和/proc/[pid]/gid_map两个文件中写入对应的绑定信息可以实现这一点,格式如下。
1 | ID-inside-ns ID-outside-ns length |
写这两个文件需要注意以下几点。
- 两个文件只允许由拥有该user namespace中CAP_SETUID权限的进程写入一次,不允许修改。
- 写入的进程必须是该user namespace的父namespace或者子namespace。
- 第一个字段ID-inside-ns表示新建的user namespace中对应的user/group ID,第二个字段ID-outside-ns表示namespace外部映射的user/group ID。最后一个字段表示映射范围,通常填1,表示只映射一个,如果填大于1的值,则按顺序建立一一映射。
明白了上述原理,我们再次修改代码,添加设置uid和guid的函数。测试的代码如下:
1 |
|
编译后即可看到user已经变成了root。
1 | $ gcc userns.c -Wall -lcap -o userns && ./userns |
至此,你就已经完成了绑定的工作,可以看到演示全程都是在普通用户下执行的。最终实现了在user namespace中成为了root而对应到外面的是一个uid为1000的普通用户。
讲完了user namespace,我们再来谈谈Docker。虽然Docker目前尚未使用user namespace,但是他用到了我们在user namespace中提及的Capabilities机制。从内核2.2版本开始,Linux把原来和超级用户相关的高级权限划分成为不同的单元,称为Capability。这样管理员就可以独立对特定的Capability进行使能或禁止。Docker虽然没有使用user namespace,但是他可以禁用容器中不需要的Capability,一次在一定程度上加强容器安全性。
总结
容器的隔离实现基本就是通过Linux内核提供的这6种namespace实现。但是容器依旧没有实现完全的环境隔离。比如: SELinux,Cgroups以及/sys,/proc/sys, /dev/sd*等目录下的资源依据是没有被隔离的。因此我们通常使用的ps, top命令查看到的数据依旧是宿主机的数据。因为它们的数据来源于/proc等目录下的文件。如果想要在可视化的角度来实现这方便的可视化隔离。可以看看之前调研的lxcfs对docker容器隔离。
参考
http://docs.wixstatic.com/ugd/295986_d73d8d6087ed430c34c21f90b0b607fd.pdf
http://ramirose.wixsite.com/ramirosen
http://www.infoq.com/cn/articles/docker-kernel-knowledge-namespace-resource-isolation?utm_source=infoq&utm_campaign=user_page&utm_medium=link
http://hustcat.github.io/namespace-implement-1/
http://abcdxyzk.github.io/blog/2015/08/06/namespace2/