上篇文章介绍了deployment controller的基本原理及功能,kube-controller-manager之Deployment Controller源码解析 。并了解了deployment, replicaset和pod三者之间的关系。这篇文章就重点对replicaset controller的源码进行深入的分析下。
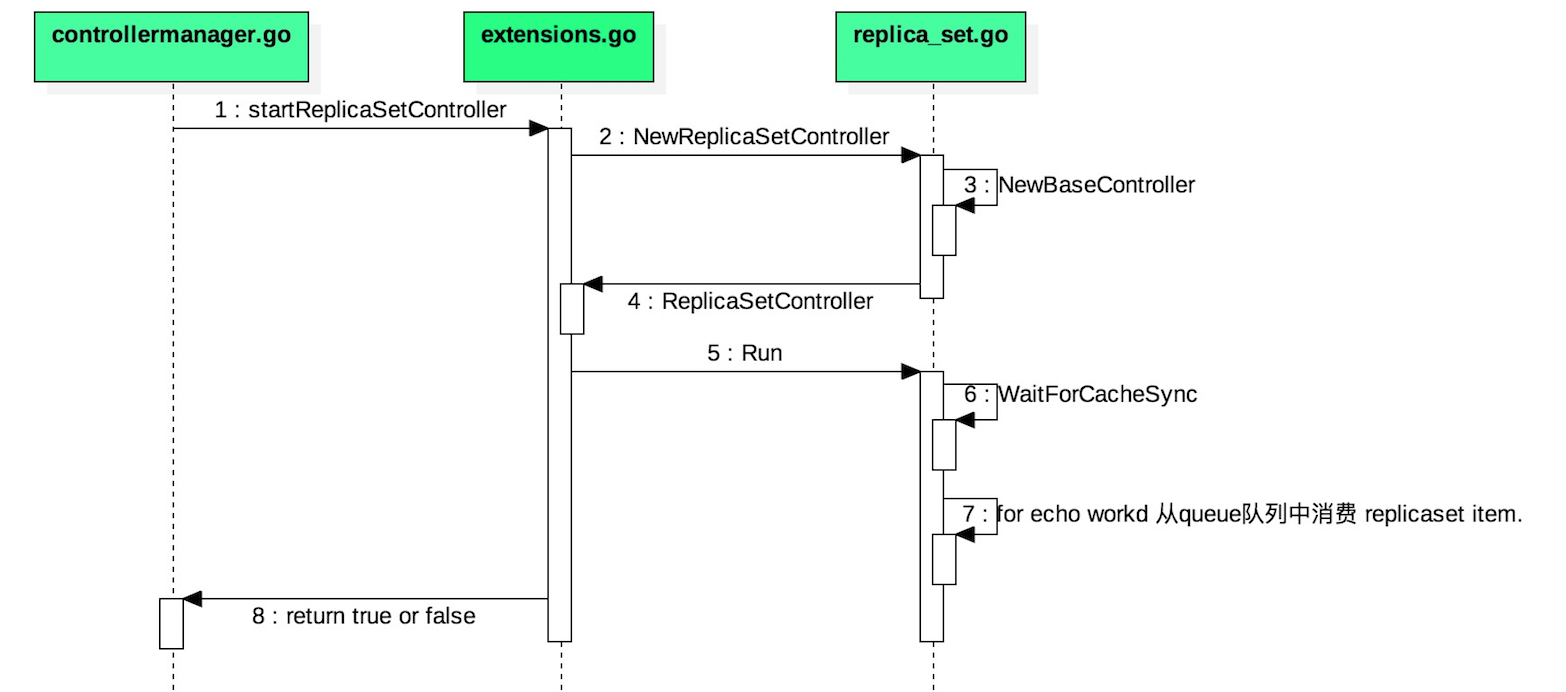
replicaset controller的启动流程 这张图是replicaset controller的启动流程,和之前介绍的deployment controller启动流程基本一致。
kube-controller-manager会在启动的时候把下面的所有被管理的控制器都启动。其中任何一个控制器启动失败,kube-controller-manager则不会正常的启动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 func NewControllerInitializers () map[string]InitFunc { controllers := map[string]InitFunc {} controllers["endpoint" ] = startEndpointController controllers["replicationcontroller" ] = startReplicationController controllers["podgc" ] = startPodGCController controllers["resourcequota" ] = startResourceQuotaController controllers["namespace" ] = startNamespaceController controllers["serviceaccount" ] = startServiceAccountController controllers["garbagecollector" ] = startGarbageCollectorController controllers["daemonset" ] = startDaemonSetController controllers["job" ] = startJobController controllers["deployment" ] = startDeploymentController controllers["replicaset" ] = startReplicaSetController controllers["horizontalpodautoscaling" ] = startHPAController controllers["disruption" ] = startDisruptionController controllers["statefulset" ] = startStatefulSetController controllers["cronjob" ] = startCronJobController controllers["csrsigning" ] = startCSRSigningController controllers["csrapproving" ] = startCSRApprovingController controllers["csrcleaner" ] = startCSRCleanerController controllers["ttl" ] = startTTLController controllers["bootstrapsigner" ] = startBootstrapSignerController controllers["tokencleaner" ] = startTokenCleanerController controllers["service" ] = startServiceController controllers["node" ] = startNodeController controllers["route" ] = startRouteController controllers["persistentvolume-binder" ] = startPersistentVolumeBinderController controllers["attachdetach" ] = startAttachDetachController controllers["persistentvolume-expander" ] = startVolumeExpandController controllers["clusterrole-aggregation" ] = startClusterRoleAggregrationController controllers["pvc-protection" ] = startPVCProtectionController return controllers }
其中就包含我们这篇文章介绍的ReplicaSe Controlelr:
1 controllers["replicaset" ] = startReplicaSetController
在startReplicaSetController方法中,对NewReplicaSetController对象进行初始化,NewReplicaSetController结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 type ReplicaSetController struct { schema.GroupVersionKind kubeClient clientset.Interface podControl controller.PodControlInterface burstReplicas int syncHandler func(rsKey string) error expectations *controller.UIDTrackingControllerExpectations rsLister extensionslisters.ReplicaSetLister rsListerSynced cache.InformerSynced podLister corelisters.PodLister podListerSynced cache.InformerSynced queue workqueue.RateLimitingInterface }
其中syncHandler是replicaset的核心逻辑入口,replica set watch到的所有replicaset资源对象都会被放到queue工作队列中。然后在Run的时候启动指定ConcurrentDeploymentSyncs数量的goroutine从queue消费去执行syncHandler部分的核心逻辑。
好了,ReplicaSet Controlelr的启动流程现在没有问题了,下面我们就介绍下ReplicaSet Controller的核心逻辑:syncReplicaSet。
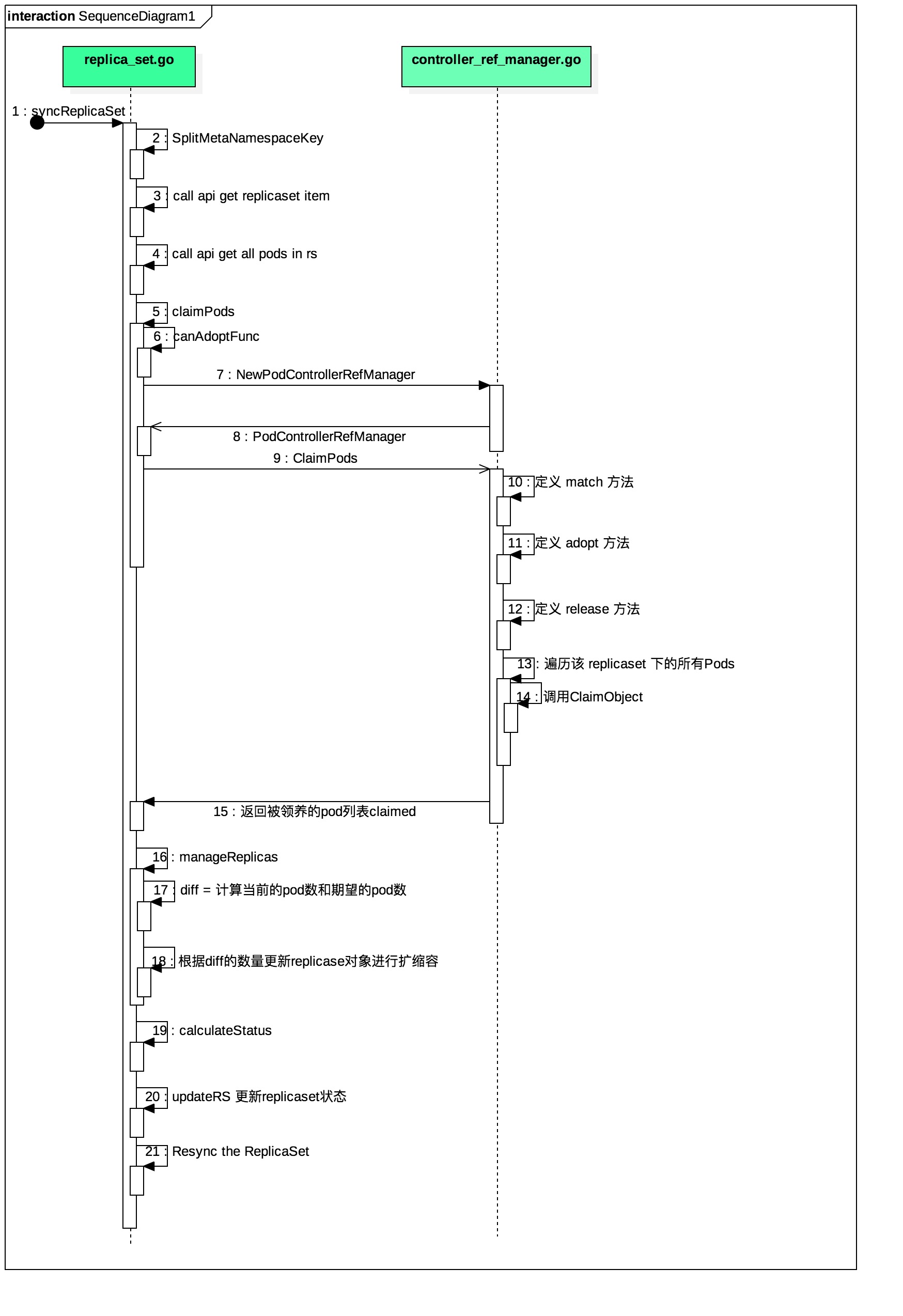
replicaset controller 核心逻辑解析 下面的这张图是对replicaset controller核心逻辑的梳理,我们就借着这张图,给大家介绍下replicaset controller的底层实现。
syncReplicaSet: replicaset核心逻辑的入口。
SplitMetaNamespaceKey: 通过replicaset watch的key, 对该key进行切分。最终切分成namespace和name。在通过获取的namespace和name获取所需要的replicaset对象和该namespaces下的所有状态处于Ready的pod。
1 2 3 4 5 6 rs, err := rsc.rsLister .ReplicaSets (namespace).Get(name) if errors.IsNotFound(err) { glog.V(4 ).Infof("%v %v has been deleted" , rsc.Kind , key) rsc.expectations .DeleteExpectations (key) return nil }
1 2 3 4 5 6 7 8 9 10 11 allPods, err := rsc.podLister.Pods(rs.Namespace).List (labels.Everything()) if err != nil { return err } var filteredPods []*v1.Pod for _, pod := range allPods { if controller.IsPodActive(pod) { filteredPods = append (filteredPods, pod) } }
claimPods: 该函数的功能是对指定replicaset下的pod进行领养和释放。最终返回属于该replicaset下的所有的pod.
manageReplicas: 通过claimPods函数获取replicaset下当前领养的pod与replicaset的期望副本数进行diff,如果diff < 0 则对replicaset的副本数已幂等的形式进行扩容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 successfulCreations, err := slowStartBatch(diff, controller.SlowStartInitialBatchSize , func() error { boolPtr := func(b bool) *bool { return &b } controllerRef := &metav1.OwnerReference{ APIVersion: rsc.GroupVersion().String(), Kind: rsc.Kind , Name: rs.Name , UID: rs.UID , BlockOwnerDeletion: boolPtr(true), Controller: boolPtr(true), } err := rsc.podControl .CreatePodsWithControllerRef (rs.Namespace , &rs.Spec .Template , rs, controllerRef) if err != nil && errors.IsTimeout(err) { return nil }
上面slowStartBatch函数的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func slowStartBatch (count int , initialBatchSize int , fn func () error ) (int , error) remaining := count successes := 0 for batchSize := integer.IntMin(remaining, initialBatchSize); batchSize > 0 ; batchSize = integer.IntMin(2 *batchSize, remaining) { errCh := make (chan error, batchSize) var wg sync.WaitGroup wg.Add(batchSize) for i := 0 ; i < batchSize; i++ { go func () defer wg.Done() if err := fn(); err != nil { errCh <- err } }() } wg.Wait() curSuccesses := batchSize - len (errCh) successes += curSuccesses if len (errCh) > 0 { return successes, <-errCh } remaining -= batchSize } return successes, nil }
如果diff >0, 则需要对replicaset进行pod缩容处理。
calculateStatus: 计算当前replicaset的状态,并更新replicaset的状态。
1 2 3 4 5 6 7 8 9 10 rs = rs.DeepCopy() new Status : updatedRS, err :new Status ) if err != nil { return err }
这样一次replicaset的处理就完成了。主要的流程就是这样,细节部分由于篇幅问题,这里就不太细的介绍了。
总结 1.首先通过replicaset controller通过watch api-server获取需要处理replicaset对象的key。ready的pod,并依据match, adopt, release对属于该replicaset下的Pod进行领养。replicaset下的pod与replicaset期望的副本数进行diff,决定是否需要扩缩容pod.replicaset的状态信息。