GPU Container on Kubernetes
在机器学习,深度学习中,使用GPU加快对模型的训练是不可避免的。由于公司的搜索实验室和人工智能研究院都想使用容器服务平台已容器的方式部署他们的服务,前提就是需要kubernetes对GPU支持。值得高兴的是kubernetes从1.6版本就已经支持了对GPU的支持(只支持单容器单卡),并且kubernetes团队在1.9版本支持了多容器多卡及对GPU监控指标的暴露。
注意: 现在kubernetes只支持Nvidia GPU.
深度学习在部署上面临的一些问题
- 不同的训练框架(如:caffe, tensorflow…),可能对依赖库版有不同版本的需求。
- 在训练模型的时候,对底层的运行时有不同的需求(如: CentOS, Ubuntu…)。
- 不同的学习模型需要不同版本的Nvidia GPU(如: k80, k40m, p4,p40,v100)和驱动。
- 如何能快速的对服务进行弹性扩缩容。
- 高效的使用GPU资源。(对于这点,现在容器对GPU的资源浪费还是没有根本性的解决,官方还没有支持多容器同卡的使用,等待官方后期支持)。
针对上面提出的这些问题,我们下面介绍下如何使用容器方式来逐一解决这些问题。
为什么以容器的方式部署GPU服务
- 基于容器技术,用户可以根据自己的需要选择自己的训练框架(caffe, tensorflow…),底层的运行时(CentOS, Ubuntu)来针对自己的场景制作镜像,并且可以基于Kubernetes的lable机制来选择需要使用的Nvidia GPU型号并对容器进行快速的扩缩容。
基于容器技术,可以对GPU的设备进行隔离。每个容器只能看到它使用的GPU设备。
如: 在容器的resources(manifest文件)处指定该容器使用的GPU数量, 并创建该容器,进入(exec)到容器中查看使用的GPU卡的数量是2:
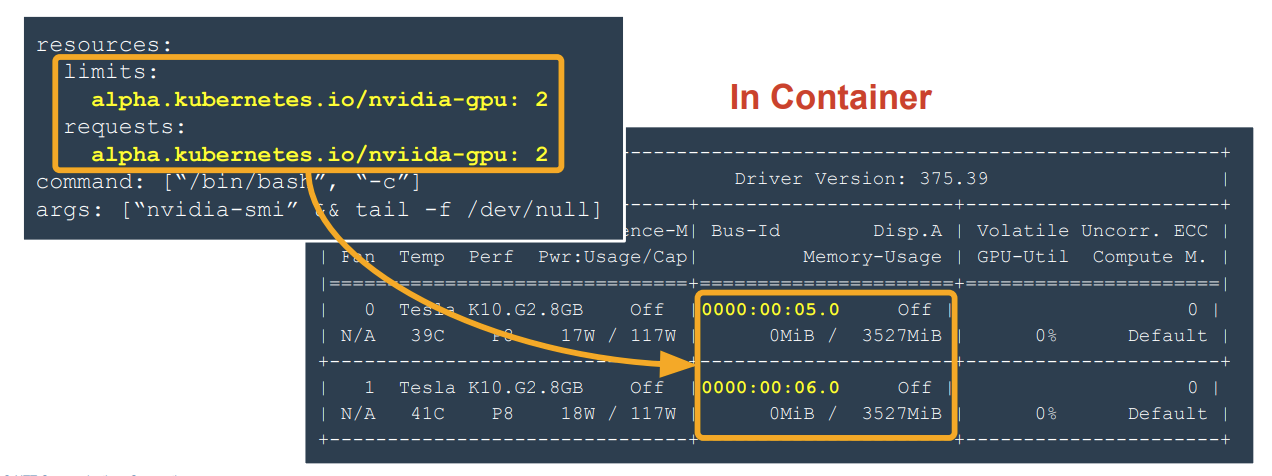
并且在容器中可以看到容器已经对GPU进行了隔离:
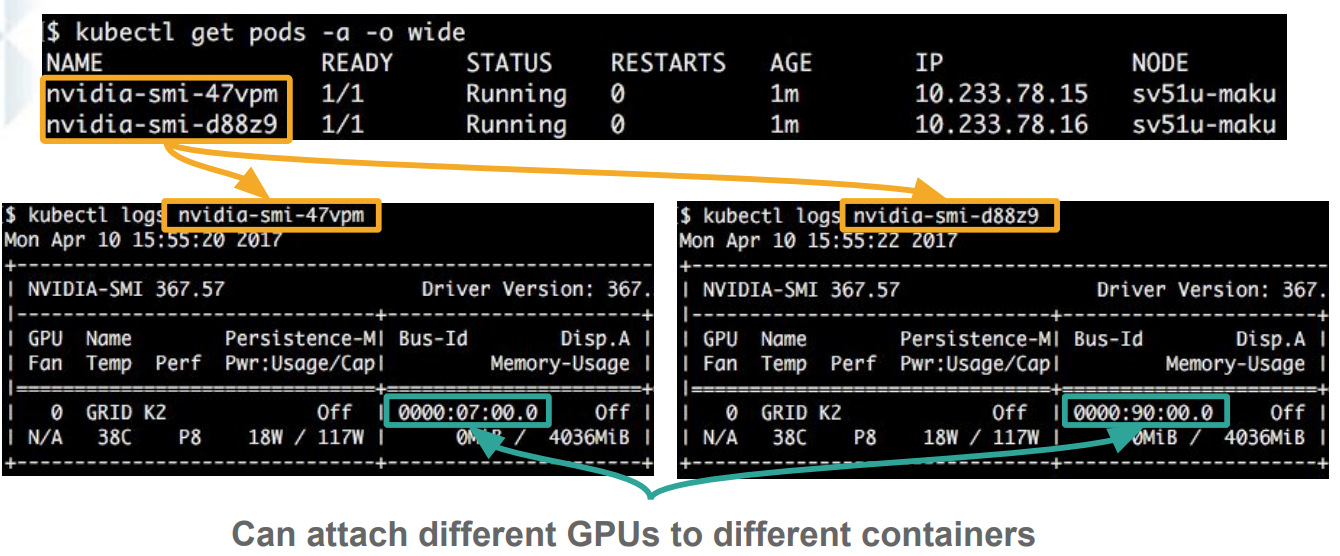
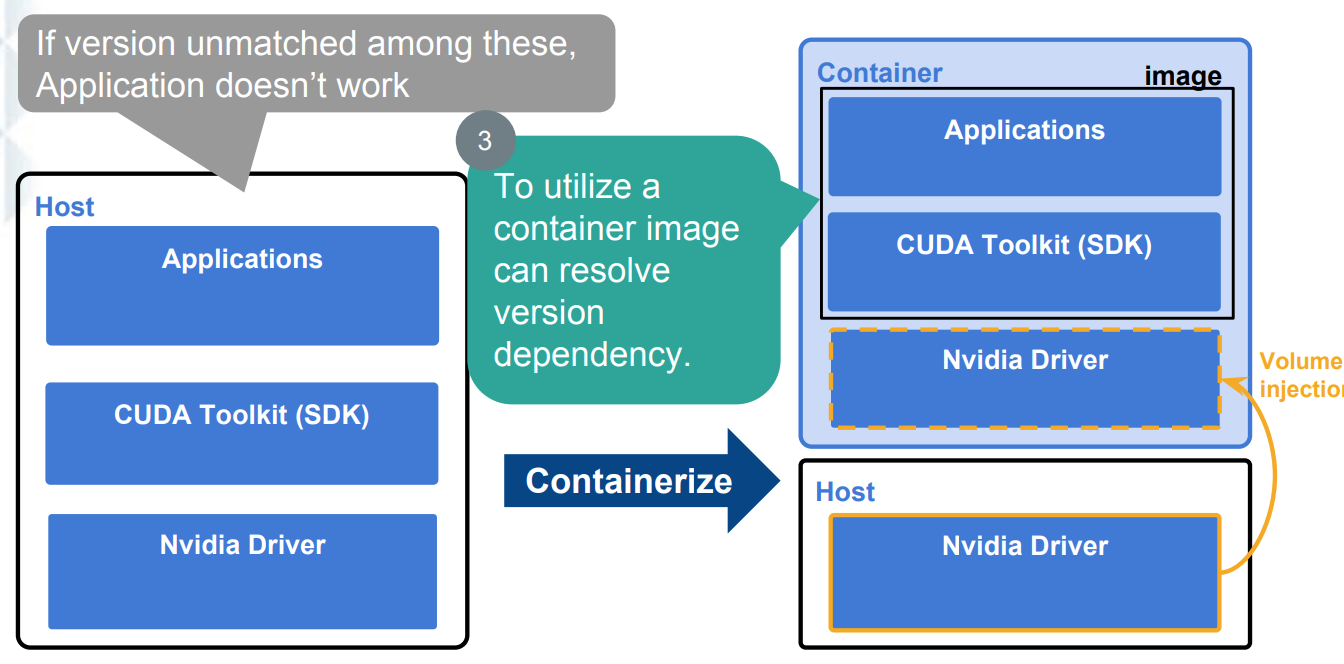
- 底层的Nvidia Driver对用户不可见,用户只需要关心上层的业务逻辑即可。使用容器的方式,容器服务平台的管理员可以在部署GPU机器的时候,将驱动安装完成,用户端在创建容器的时候,会以卷(volume)的形式将Cuda库挂载到容器里面,供上层的服务使用。如下图是传统方式和容器化方式的一个对比图:
多维度(Deployment, Pod, Container)的对GPU的资源使用情况进行监控,kubernetes 1.9版本暴露了针对GPU容器的显存和使用率的指标(而不需要直接通过调用NVML库来获取GPU卡的使用情况)。kubernetes暴露出来的metrics如下:
- container_accelerator_memory_used_bytes
- container_accelerator_duty_cycle
如何实现GPU容器作为服务
GPU集群部署
- 安装 Nvidia Driver
- 安装 docker
- 安装 nvidia-docker1.0(暂时还没有使用nvidia-docker 2.0)
- 验证
- 存在的问题,及解决方案
安装 Nvidia Driver
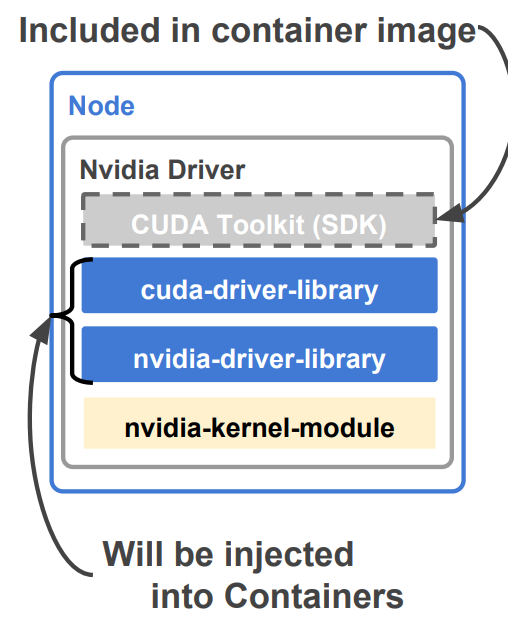
Nvidia Driver驱动在宿主机上的示意图:
从ELrepo源中安装驱动,添加ELrepo数据源:http://elrepo.org/tiki/tiki-index.php
1 | sudo rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org |
安装显卡检查程序:
1 | sudo yum install nvidia-detect |
检查显卡型号,并选择对应的驱动:
1 | nvidia-detect -v |
根据nvidia-detest的输出信息,可以知道显卡的型号,以及要使用的驱动程序版本.如384.98
1 | yum install kmod-nvidia-384.98-1.el7_4.elrepo.x86_64 |
重启服务器:
1 | reboot |
检查nvidia模块是否加载成功:
1 | lsmod | grep nvidia |
安装docker
nvidia-docker1.0 对于docker的安装。不需要进行调整,但是如果使用的是nvidia-docker 2.0则需要进行相关的调整(会重写docker配置文件/etc/docker/daemon.json)。
1 | yum install docker-ce-18.01 -y |
安装 nvidia-docker 1.0
安装环境需求
The list of prerequisites for running nvidia-docker is described below.
For information on how to install Docker for your Linux distribution, please refer to the Docker documentation.- GNU/Linux x86_64 with kernel version > 3.10
- Docker >= 1.9 (official docker-engine, docker-ce or docker-ee only)
- NVIDIA GPU with Architecture > Fermi (2.1)
NVIDIA drivers >= 340.29 with binary nvidia-modprobe
Your driver version might limit your CUDA capabilities (see CUDA requirements)
安装nvidia-docker1.0
- Install the repository for your distribution by following the instructions here.https://nvidia.github.io/nvidia-docker/
Install the nvidia-docker package
1
sudo yum install nvidia-docker
The package installation will automatically setup the nvidia-docker-plugin and depending on your distribution, register it with the init system.
启动 nvidia-docker
编辑 nvidia-docker.service 文件:
1
systemctl edit nvidia-docker.service
文件内容:
1
2
3[Service]
ExecStart=
ExecStart=/usr/bin/nvidia-docker-plugin -s $SOCK_DIR -d /usr/local/nvidia-driver1
systemctl start nvidia-docker
启动后,它会创建一个数据卷nvidia_driver_384. 98,且对应着宿主机上会生成1个目录/usr/local/nvidia-driver/nvidia_driver/384.98/.
1 | docker volume ls |
如果nvidia-docker nvidia_driver_384. 98数据卷没有,则肯定是启动有问题,可以根据日志排查定位问题,如下面的错误信息:
1 | Error: mkdir /usr/local/nvidia-driver/: permission denied |
这个时候需要手动创建,创建方式:
1 | mkdir -p /usr/local/nvidia-driver |
5.运行GPU容器检查是否正常
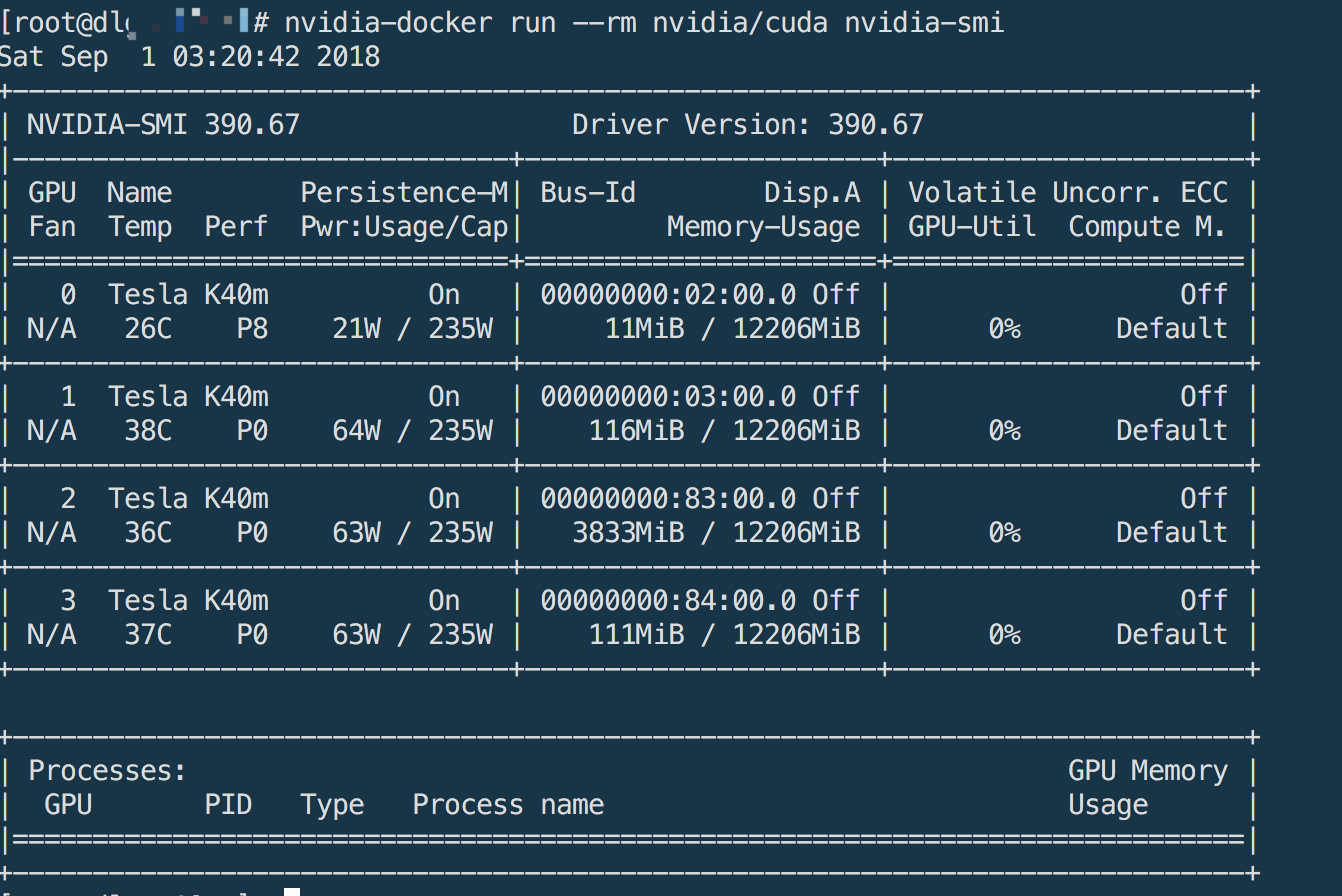
1 | nvidia-docker run --rm nvidia/cuda nvidia-smi |
能正常输出GPU信息说明安装没有问题。
输出内容如下:
存在的问题及解决方案
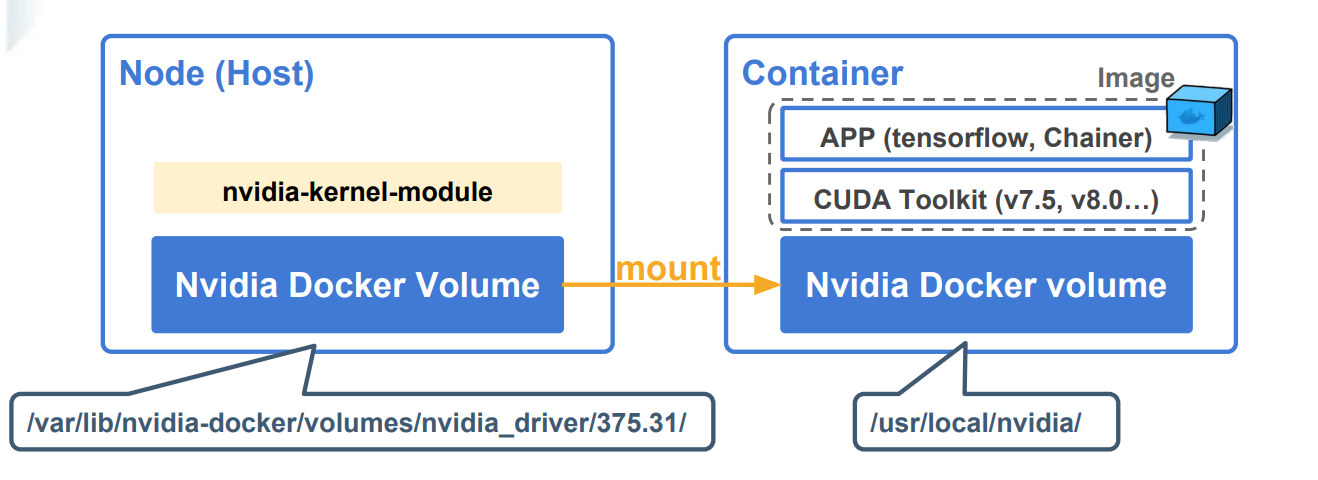
直接将nvidia驱动挂载到容器内部:
类似下图:
如果向现在这样直接把/usr/local/nvidia-driver/nvidia_driver/384.98/驱动已卷的形式通过kubernetes的manifest的形式挂载到容器中,只能针对384.98这种驱动型号,可能存在不同的GPU机器使用不同型号的驱动,这样做是不可行的,所有可以使用link的方式统一驱动的挂载路径,如下图所示:
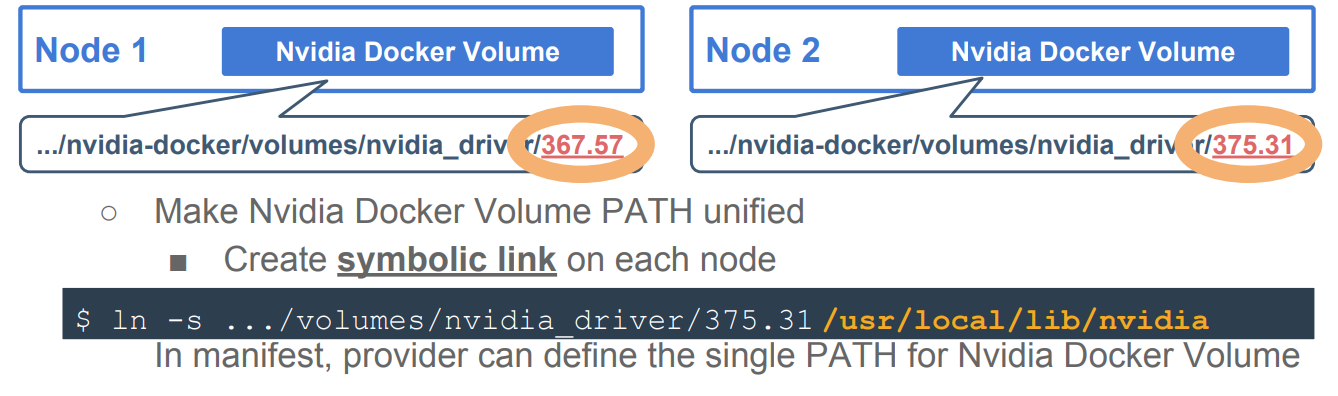
通过这种方式不同型号的驱动,在kubernetes这层是无感知的。
参考:
https://www.openstack.org/assets/presentation-media/OpenStack-Boston-Summit-Presentation.pdf
https://www.openstack.org/videos/boston-2017/container-as-a-service-on-gpu-cloud-our-decision-among-k8s-mesos-docker-swarm-and-openstack-zun
https://github.com/NVIDIA/nvidia-docker/wiki/Installation-(version-1.0))