浅谈Cgroups
说起容器监控,首先会想到通过Cadvisor, Docker stats等多种方式获取容器的监控数据,并同时会想到容器通过Cgroups实现对容器中的资源进行限制。但是这些数据来自哪里,并且如何计算的?答案是Cgroups。最近在写docker容器监控组件,在深入Cadvisor和Docker stats源码发现数据都来源于Cgroups。了解之余,并对Cgroups做下笔记。
Cgroups 介绍
Cgroups 是 control groups 的缩写,是Linux内核提供的一种可以限制,记录,隔离进程组(process groups)所使用物理资源的机制。最初有google工程师提出,后来被整合进Linux的内核。因此,Cgroups为容器实现虚拟化提供了基本保证,是构建Docker,LXC等一系列虚拟化管理工具的基石。
Cgroups 作用
- 资源限制(Resource limiting): Cgroups可以对进程组使用的资源总额进行限制。如对特定的进程进行内存使用上限限制,当超出上限时,会触发OOM。
- 优先级分配(Prioritization):通过分配的CPU时间片数量及硬盘IO带宽大小,实际上就相当于控制了进程运行的优先级。
- 资源统计(Accounting): Cgroups可以统计系统的资源使用量,如CPU使用时长、内存用量等等,这个功能非常适用于计费。
- 进程控制(Control):Cgroups可以对进程组执行挂起、恢复等操作。
Cgroups 组成
Cgroups主要由task,cgroup,subsystem及hierarchy构成。下面分别介绍下各自的概念。
- task: 在Cgroups中,task就是系统的一个进程。
- cgroup: Cgroups中的资源控制都以cgroup为单位实现的。cgroup表示按照某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个cgroup,也可以从某个cgroup迁移到另外一个cgroup。
- subsystem: Cgroups中的subsystem就是一个资源调度控制器(Resource Controller)。比如CPU子系统可以控制CPU时间分配,内存子系统可以限制cgroup内存使用量。
- hierarchy: hierarchy由一系列cgroup以一个树状结构排列而成,每个hierarchy通过绑定对应的subsystem进行资源调度。hierarchy中的cgroup节点可以包含零或多个子节点,子节点继承父节点的属性。整个系统可以有多个hierarchy。
Subsystems,Hierarchies,Control Groups 和 Tasks 的关系
Subsystems, Hierarchies,Control Group和Tasks之间有许多的规则,下面介绍下:
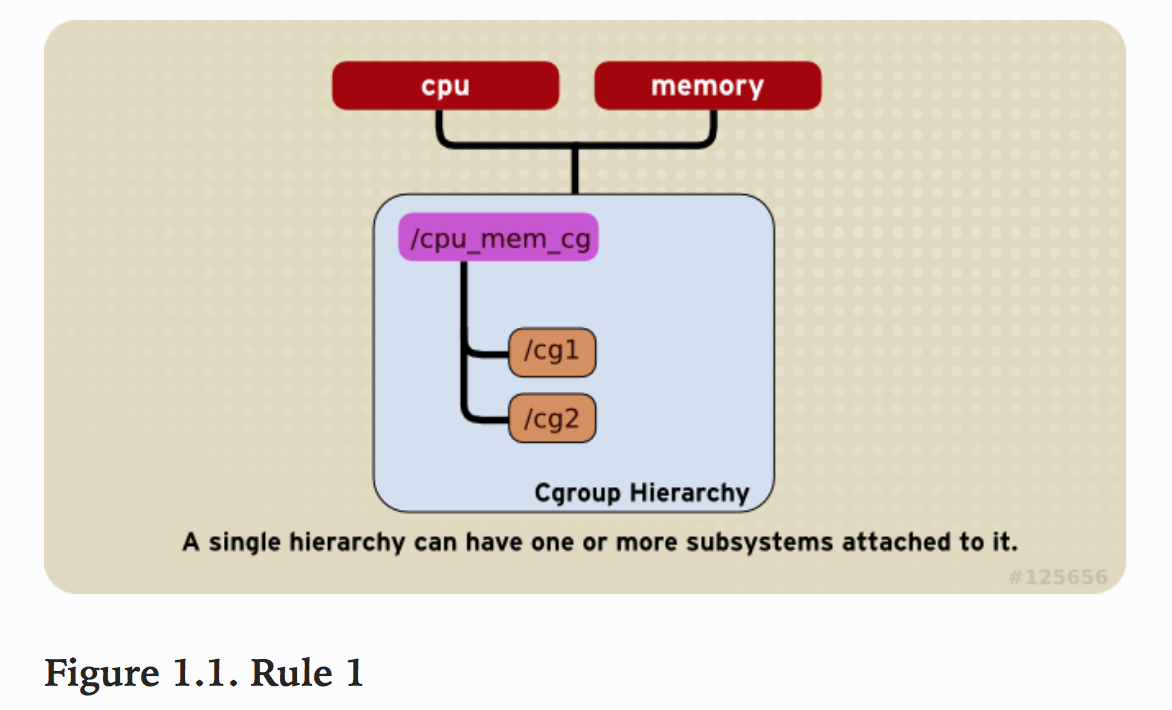
规则1
- 同一个hierarchy能够附加一个或多个subsystem。
如下图将cpu和memory subsystems(或者任意多个subsystems)附加到同一个hierarchy。
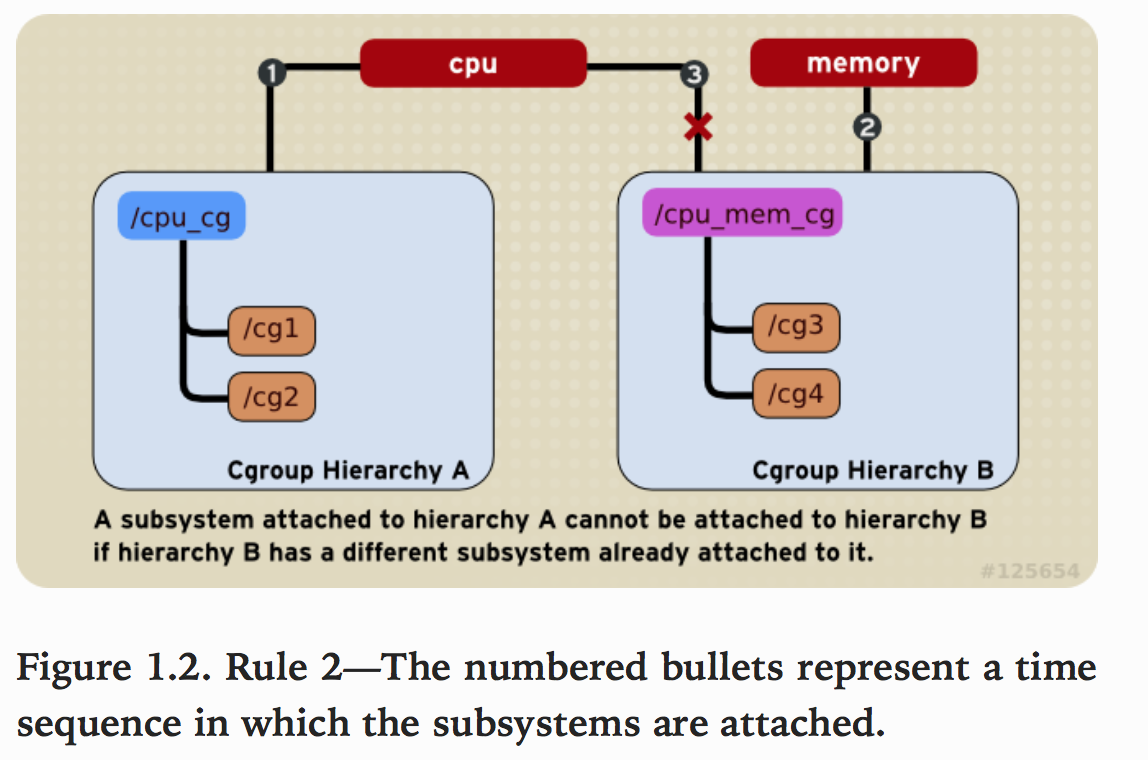
规则2
- 一个subsystem只能附加到一个hierarchy上。
如下图cpu subsystem已经附加到了hierarchy A,并且memory subsystem已经附加到了hierarchy B。因此cpu subsystem不能在附加到hierarchy B。
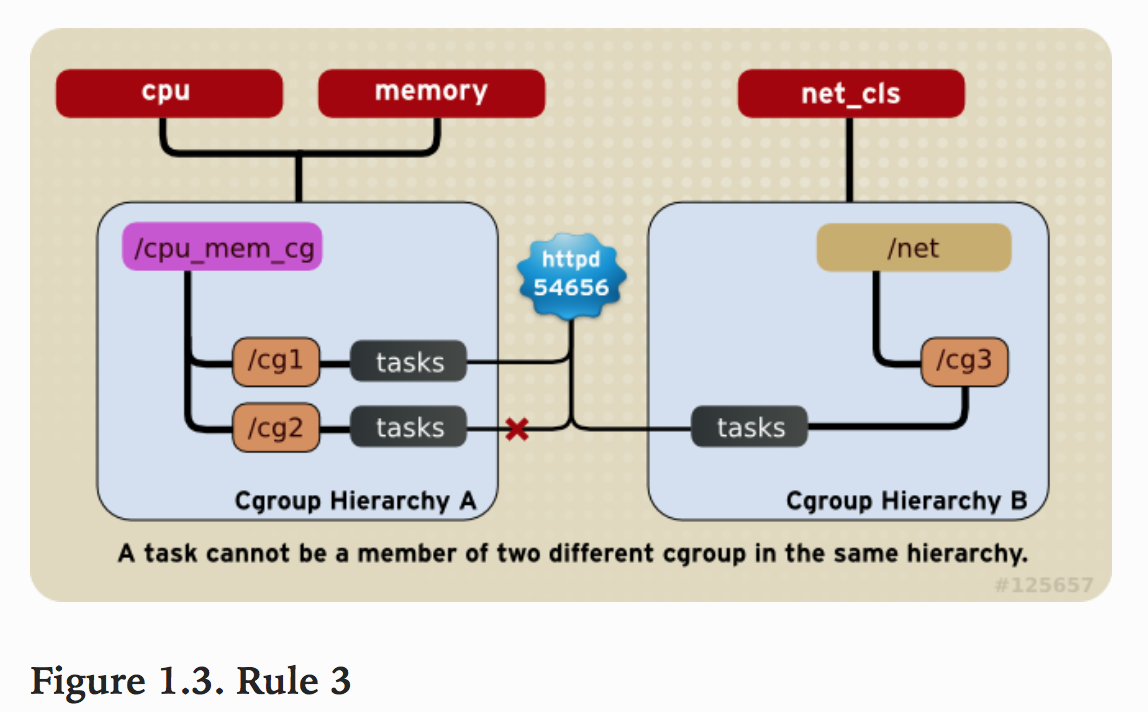
规则3
系统每次新建一个hierarchy时,该系统上的所有task默认构成了这个新建的hierarchy的初始化cgroup,这个cgroup也称为root cgroup。对于你创建的每个hierarchy,task只能存在于其中一个cgroup中,即一个task不能存在于同一个hierarchy的不同cgroup中,但是一个task可以存在在不同hierarchy中的多个cgroup中。如果操作时把一个task添加到同一个hierarchy中的另一个cgroup中,则会从第一个cgroup中移除
如下图,cpu和memory subsystem被附加到cpu_mem_cg的hierarchy。而net_cls subsystem被附加到net_cls hierarchy。并且httpd进程被同时加到了cpu_mem_cg hierarchy的cg1 cgroup中和net hierarchy的cg3 cgroup中。并通过两个hierarchy的subsystem分别对httpd进程进行cpu,memory及网络带宽的限制。
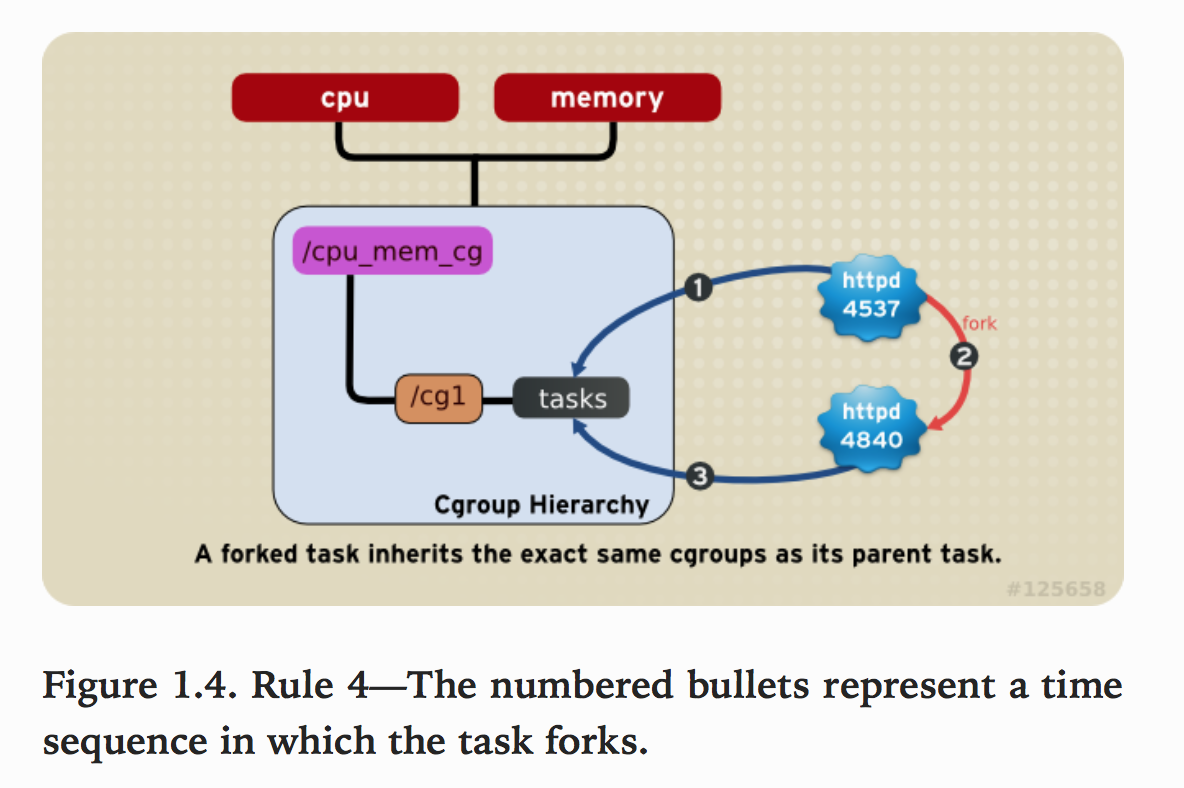
规则4
系统中的任何一个task(Linux中的进程)fork自己创建一个子task(子进程)时,子task会自动的继承父task cgroup的关系,在同一个cgroup中,但是子task可以根据需要移到其它不同的cgroup中。父子task之间是相互独立不依赖的。
如下图,httpd进程在cpu_and_mem hierarchy的/cg1 cgroup中并把PID 4537写到该cgroup的tasks中。之后httpd(PID=4537)进程fork一个子进程httpd(PID=4840)与其父进程在同一个hierarchy的统一个cgroup中,但是由于父task和子task之间的关系独立不依赖的,所以子task可以移到其它的cgroup中。
使用 Control Cgroups
我们直接使用shell 命令直接操作hierarchy并设置cgroup参数。在centos6上也可以直接使用libcgroup提供的工具可简化对cgroup的使用。
1 | yum install libcgroup |
Creating a Hierarchy and Attaching Subsystems
使用shell命令创建hierarchy并附加subsystems到该hierarchy上。
作为root为hierarchy创建一个mount point。并且在mount point中包含cgrou的名字。
1 | mkdir /cgroup/name |
例如:
1 | mkdir /cgroup/cpu_and_mem |
接下来使用mount命令去挂载hierarchy并附加一个或多个subsystem到该hierarchy上。
1 | # mount -t cgroup -o subsystems name /cgroup/name |
例如:
1 | mount -t cgroup -o cpu,cpuset,memory cpu_and_mem /cgroup/cpu_and_mem |
如果想在已有的hierarchy上attch或detach subsystem,可以使用remount操作,例如我们想detach掉memory subsystem:
1 | mount -t cgroup -o remount,cpu,cpuset cpu_and_mem /cgroup/cpu_and_mem |
Unmounting a Hierarchy
可以直接用umount命令来unmount一个已有的Hierarchy:
1 | umount /cgroup/name |
例如:
1 | umount /cgroup/cpu_and_mem |
Creating Control Groups
直接使用shell命令mkdir创建一个子cgroup:
1 | # mkdir /cgroup/hierarchy/name/child_name |
例如:
1 | mkdir /cgroup/cpu_and_mem/group1 |
Setting Control Cgroup Parameters
在group1中使用echo命令插入0-1到cpuset.cpus,来限制该cgroup中的tasks只能跑在0和1的cpu core上。如下:
1 | echo 0-1 > /cgroup/cpu_and_mem/group1/cpuset.cpus |
Moving a Process to a Control Group
只要将想要限制的进程PID,追加到想要的cgroup的tasks文件中就可以了。例如:将PID=1701的进程放到/cgroup/cpu_and_mem/group1/的cgroup中。
1 | echo 1701 > /cgroup/cpu_and_mem/group1/tasks |
Subsystem 介绍
- blkio:
blkio子系统控制并监控cgroup中的task对块设备的I/O的访问。如:限制访问及带宽等。 - cpu: 主要限制进程的cpu使用率。
- cpuacct: 可以统计cgroup中进程的cpu使用报告。
- cpuset: 可以为cgroup中的进程分配独立的cpu和内存节点。
- memory: 自动生成cgroup中task使用的内存资源报告,并对该cgroup的task进行内存使用限制。
- devices: 可以控制进程能否访问某些设备。
- net_cls: 使用等级标识符(clssid)标记网络数据包,可允许Linux流量控制程序(tc)识别从具体cgroup中生成的数据包。
- freezer: 可以挂起挂起或回复cgroup中的进程。
- ns: 可以使不同cgroup中的进程使用不同的namespace。
容器使用Cgroups进行资源限制
无论是使用docker run方式直接创建容器,还是通过各类容器编排工具(如:Kubernetes)创建容器,对于容器的限制本质都是通过Cgroups。我们分别使用这两种方式来创建容器并观察cgroups:
测试环境:
1 | 操作系统 Centis 7.2 |
- 使用
docker run方式创建容器:
限制CPU share,创建两个容器,则会在运行该容器宿主机的/sys/fs/cgroup/cpu/docker/下分别创建两个子cgroup,格式如下:
1 | # /sys/fs/cgroup/cpu/docker/<container_id>/ |
创建一个容器,并设置
--cpu-shares参数为:1024*10

查看该容器cgroup的cpu.shares文件内容如下:

创建一个容器,并设置
--cpu-shares参数为:2014*14

查看该容器cgroup的cpu.shares文件内容如下:

两个容器使用cpu的stats,一个容器分到14核的相对cpu计算时间,另一个容器分到10核的相对cpu计算时间:

- 限制容器内存使用量
创建一个容器,限制容器能使用的内存上限为1024M

查看容器memory的stats,内存使用率100%

当容器使用的内存量超过
1024M,则容器会被kill -9掉。

使用Kubenetes容器编排工具创建容器:
使用
kubernetes编排工具创建的容器,则与容器关联的cgroup均在运行该容器宿主机的/sys/fs/cgroup/cpu/kubepods/下,具体的格式如下所示:1
# /sys/fs/cgroup/cpu/kubepods/pod<pod_id>/<container_id>
使用Pod创建一个容器,对应的yaml文件内容如下:
1 | apiVersion: v1 |
在运行该容器的宿主机上查看该容器的cgroup信息,会观察到cpu.shares为1核,memory.limit_in_bytes为2G.
